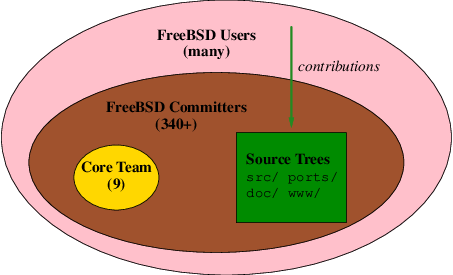
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
r151864 | bde | 2005-10-29 09:34:50 -0700 (Sat, 29 Oct 2005) | 13 lines
Changed paths:
M /head/lib/msun/src/e_rem_pio2f.c
Use double precision to simplify and optimize arg reduction for small
and medium size args too: instead of conditionally subtracting a float
17+24, 17+17+24 or 17+17+17+24 bit approximation to pi/2, always
subtract a double 33+53 bit one. The float version is now closer to
the double version than to old versions of itself -- it uses the same
33+53 bit approximation as the simplest cases in the double version,
and where the float version had to switch to the slow general case at
|x| == 2^7*pi/2, it now switches at |x| == 2^19*pi/2 the same as the
double version.
This speeds up arg reduction by a factor of 2 for |x| between 3*pi/4 and
2^7*pi/4, and by a factor of 7 for |x| between 2^7*pi/4 and 2^19*pi/4.#REV #WHO #DATE #TEXT
176410 bde 2008-02-19 07:42:46 -0800 (Tue, 19 Feb 2008) #include <sys/cdefs.h>
176410 bde 2008-02-19 07:42:46 -0800 (Tue, 19 Feb 2008) __FBSDID("$FreeBSD$");
2116 jkh 1994-08-19 02:40:01 -0700 (Fri, 19 Aug 1994)
2116 jkh 1994-08-19 02:40:01 -0700 (Fri, 19 Aug 1994) /* __ieee754_rem_pio2f(x,y)
8870 rgrimes 1995-05-29 22:51:47 -0700 (Mon, 29 May 1995) *
176552 bde 2008-02-25 05:33:20 -0800 (Mon, 25 Feb 2008) * return the remainder of x rem pi/2 in *y
176552 bde 2008-02-25 05:33:20 -0800 (Mon, 25 Feb 2008) * use double precision for everything except passing x
152535 bde 2005-11-16 18:20:04 -0800 (Wed, 16 Nov 2005) * use __kernel_rem_pio2() for large x
2116 jkh 1994-08-19 02:40:01 -0700 (Fri, 19 Aug 1994) */
2116 jkh 1994-08-19 02:40:01 -0700 (Fri, 19 Aug 1994)
176465 bde 2008-02-22 07:55:14 -0800 (Fri, 22 Feb 2008) #include <float.h>
176465 bde 2008-02-22 07:55:14 -0800 (Fri, 22 Feb 2008)
2116 jkh 1994-08-19 02:40:01 -0700 (Fri, 19 Aug 1994) #include "math.h"已添加 abc(4) 支持,包括对 frobnicator 兼容性的支持。新增了 abc(4) 驱动程序,带来了对 Yoyodyne 公司 Frobnicator 网络接口的支持。我们将 Cyberdyne Systems T800 导入到树中。0 0 1,15,24 3,6,9,12 * cd ~/doc/tools/sendcalls && git pull && ./sendcalls -s 'Lorenzo Salvadore'[[news]]
date = "2021-01-16"
title = "2020 年 10月-12月状态报告"
description = "2020 年 10 月到 12 月的状态报告现已发布,包含 42 个条目。"% w3m -cols 80 -dump https://www.FreeBSD.org/status/report-2021-01-2021-03/ > /tmp/report-2021-01-2021-03.txt
% ntpq -c 'rv 0 leap'# pkg install cups[system=10]
add path 'unlpt*' mode 0660 group cups
add path 'ulpt*' mode 0660 group cups
add path 'lpt*' mode 0660 group cups
add path 'usb/X.Y.Z' mode 0660 group cupscupsd_enable="YES"
devfs_system_ruleset="system"application/octet-stream# service devfs restart
# service cupsd restartipp://server-name-or-ip/printers/printernamehttp://server-name-or-ip:631/printers/printernameServerName server-iphttp://server-name-or-ip:631/printers/printername# 在 error_log 中记录一般信息 - 若进行故障排除,请将 "info" 改为 "debug"...
LogLevel info
# 管理员用户组...
SystemGroup wheel
# 在端口 631 上监听连接。
Port 631
#Listen localhost:631
Listen /var/run/cups.sock
# 显示局域网共享的打印机。
Browsing On
BrowseOrder allow,deny
#BrowseAllow @LOCAL
BrowseAllow 192.168.1.* # 更改为本地 LAN 设置
BrowseAddress 192.168.1.* # 更改为本地 LAN 设置
# 需要身份验证时的默认身份验证类型...
DefaultAuthType Basic
DefaultEncryption Never # 注释掉此行以允许加密
# 允许 LAN 上任何计算机访问服务器
<Location />
Order allow,deny
#Allow localhost
Allow 192.168.1.* # 更改为本地 LAN 设置
</Location>
# 允许 LAN 上任何计算机访问管理员页面
<Location /admin>
#要求加密
Order allow,deny
#Allow localhost
Allow 192.168.1.* # 更改为本地 LAN 设置
</Location>
# 允许 LAN 上任何计算机访问配置文件
<Location /admin/conf>
AuthType Basic
Require user @SYSTEM
Order allow,deny
#Allow localhost
Allow 192.168.1.* # 更改为本地 LAN 设置
</Location>
# 设置默认打印机/作业策略...
<Policy default>
# 与作业相关的操作必须由所有者或管理员执行...
<Limit Send-Document Send-URI Hold-Job Release-Job Restart-Job Purge-Jobs \
Set-Job-Attributes Create-Job-Subscription Renew-Subscription Cancel-Subscription \
Get-Notifications Reprocess-Job Cancel-Current-Job Suspend-Current-Job Resume-Job \
CUPS-Move-Job>
Require user @OWNER @SYSTEM
Order deny,allow
</Limit>
# 所有管理操作都需要管理员身份验证...
<Limit Pause-Printer Resume-Printer Set-Printer-Attributes Enable-Printer \
Disable-Printer Pause-Printer-After-Current-Job Hold-New-Jobs Release-Held-New-Jobs \
Deactivate-Printer Activate-Printer Restart-Printer Shutdown-Printer Startup-Printer \
Promote-Job Schedule-Job-After CUPS-Add-Printer CUPS-Delete-Printer CUPS-Add-Class \
CUPS-Delete-Class CUPS-Accept-Jobs CUPS-Reject-Jobs CUPS-Set-Default>
AuthType Basic
Require user @SYSTEM
Order deny,allow
</Limit>
# 只有所有者或管理员可以取消或认证作业...
<Limit Cancel-Job CUPS-Authenticate-Job>
Require user @OWNER @SYSTEM
Order deny,allow
</Limit>
<Limit All>
Order deny,allow
</Limit>
</Policy>% dmesg > /tmp/dmesg.outoptions MD_ROOT # md 设备可作为潜在的根设备varsize=8192# 设备 挂载点 文件系统类型 选项 Dump Pass#
/dev/ad0s1a / ufs ro 1 1# /sbin/mount -uw partition# /sbin/mount -ur partition# disklabel -e /dev/ad0ca: 123456 0 4.2BSD 0 0# disklabel -B -r /dev/ad0c
# newfs /dev/ad0a# mount /dev/ad0a /flash# ifconfig xl0 192.168.0.10 netmask 255.255.255.0
# route add default 192.168.0.1ftp> get tarfile.tar "| tar xvf -"ftp> get tarfile.tar "| zcat | tar xvf -"# cd /
# umount /flash
# exit# touch /var/log/security /var/log/maillog /var/log/cron /var/log/messages
# chmod 0644 /var/log/*# mkdir /etc/pkg# ln -s /etc/pkg /var/db/pkg# chmod 0774 /var/log/apache
# chown nobody:nobody /var/log/apache# rm -rf apache_log_dir
# ln -s /var/log/apache apache_log_dir# pkg install ccls# pkg install llvm15# mkdir -p ~/.config/nvim/pack/lsp/start
# git clone https://github.com/prabirshrestha/vim-lsp ~/.config/nvim/pack/lsp/start/vim-lsp# mkdir -p ~/.vim/pack/lsp/start
# git clone https://github.com/prabirshrestha/vim-lsp ~/.vim/pack/lsp/start/vim-lspau User lsp_setup call lsp#register_server({
\ 'name': 'ccls',
\ 'cmd': {server_info->['ccls']},
\ 'allowlist': ['c', 'cpp', 'objc'],
\ 'initialization_options': {
\ 'cache': {
\ 'hierarchicalPath': v:true
\ }
\ }})au User lsp_setup call lsp#register_server({
\ 'name': 'clangd',
\ 'cmd': {server_info->['clangd15', '--background-index', '--header-insertion=never']},
\ 'allowlist': ['c', 'cpp', 'objc'],
\ 'initialization_options': {},
\ })function! s:on_lsp_buffer_enabled() abort
setlocal omnifunc=lsp#complete
setlocal completeopt-=preview
setlocal keywordprg=:LspHover
nmap <buffer> <C-]> <plug>(lsp-definition)
nmap <buffer> <C-W>] <plug>(lsp-peek-definition)
nmap <buffer> <C-W><C-]> <plug>(lsp-peek-definition)
nmap <buffer> gr <plug>(lsp-references)
nmap <buffer> <C-n> <plug>(lsp-next-reference)
nmap <buffer> <C-p> <plug>(lsp-previous-reference)
nmap <buffer> gI <plug>(lsp-implementation)
nmap <buffer> go <plug>(lsp-document-symbol)
nmap <buffer> gS <plug>(lsp-workspace-symbol)
nmap <buffer> ga <plug>(lsp-code-action)
nmap <buffer> gR <plug>(lsp-rename)
nmap <buffer> gm <plug>(lsp-signature-help)
endfunction
augroup lsp_install
au!
autocmd User lsp_buffer_enabled call s:on_lsp_buffer_enabled()
augroup END[
/* 现有配置开始 */
...
/* 现有配置结束 */
"clangd.arguments": [
"--background-index",
"--header-insertion=never"
],
"clangd.path": "clangd12"
][
/* 现有配置开始 */
...
/* 现有配置结束 */
"ccls.cache.hierarchicalPath": true
]# git clone https://github.com/llvm/llvm-project /path/to/llvm-projectalias intercept-build='/path/to/llvm-project/clang/tools/scan-build-py/bin/intercept-build'# intercept-build --append make buildworld buildkernel -j`sysctl -n hw.ncpu`# bear --append -- make buildworld buildkernel -j`sysctl -n hw.ncpu`options BRIDGE
options IPFIREWALL
options IPFIREWALL_VERBOSEbridge_load="YES"firewall_enable="YES"
firewall_type="open"
firewall_quiet="YES"
firewall_logging="YES"# sysctl net.link.ether.bridge.config=fxp0:0,xl0:0
# sysctl net.link.ether.bridge.ipfw=1
# sysctl net.link.ether.bridge.enable=1firewall_type="/etc/rc.firewall.local"# 以前我们已经保存状态的事项,赶紧通过
add check-state
# 丢弃 RFC 1918 网络
add drop all from 10.0.0.0/8 to any in via fxp0
add drop all from 172.16.0.0/12 to any in via fxp0
add drop all from 192.168.0.0/16 to any in via fxp0
# 允许桥接机器发送任何内容
# (如果机器没有 IP,请不要包含这些行)
add pass tcp from 1.2.3.4 to any setup keep-state
add pass udp from 1.2.3.4 to any keep-state
add pass ip from 1.2.3.4 to any
# 允许内部主机发送任何内容
add pass tcp from any to any in via xl0 setup keep-state
add pass udp from any to any in via xl0 keep-state
add pass ip from any to any in via xl0
# TCP 部分
# 允许 SSH
add pass tcp from any to any 22 in via fxp0 setup keep-state
# 仅允许邮件服务器接收 SMTP
add pass tcp from any to relay 25 in via fxp0 setup keep-state
# 仅允许由次级名称服务器 [dns2.nic.it] 执行区域传输
add pass tcp from 193.205.245.8 to ns 53 in via fxp0 setup keep-state
# 通过 ident 探针。它比等待它们超时更好
add pass tcp from any to any 113 in via fxp0 setup keep-state
# 通过“隔离”范围
add pass tcp from any to any 49152-65535 in via fxp0 setup keep-state
# UDP 部分
# 仅允许 DNS 向名称服务器发送请求
add pass udp from any to ns 53 in via fxp0 keep-state
# 通过“隔离”范围
add pass udp from any to any 49152-65535 in via fxp0 keep-state
# ICMP 部分
# 通过‘ping’
add pass icmp from any to any icmptypes 8 keep-state
# 通过由‘traceroute’生成的错误信息
add pass icmp from any to any icmptypes 3
add pass icmp from any to any icmptypes 11
# 其他一切都可疑
add drop log all from any to anyadd deny all from 1.2.3.4/8 to any in via fxp0主题:HELP!!?!??
我就是搞不懂这个该死的 FreeBSD 系统,
我很擅长这个东西,但我从未见过
这么难安装的东西,尽管我做了很多尝试,
就是没有成功,为什么你们不告诉我
我哪里做错了?主题:安装 FreeBSD 时遇到问题
我刚从 Walnut Creek 买到了 FreeBSD 2.1.5 CDROM,现在安装时遇到了很多困难。我有一台 66 MHz 的 486 机器,内存 16MB,安装了 Adaptec 1540A SCSI 控制器,一块 1.2GB 的 Quantum Fireball 硬盘和 Toshiba 3501XA CDROM 驱动器。安装过程一切正常,但在重启系统时,我收到了报错“Missing Operating System”。tcpdump -c 4000 -s 10000 -w dumpfile.bindevice bpf/*
ULISCAN.c --- 8 位块大小
1998 年 10 月1 日
1998 年 12 月 1 日
1998 年 12 月 21 日 uliscan.c 源自 ueli8.c
该版本已去除 // 注释,以便于 Sun cc 编译器使用
该程序实现了 Ueli M Maurer 的 "随机比特生成器的通用统计测试",使用 L=8
接受命令行上的文件名;将结果和其他信息写入标准输出(stdout)。
能够优雅地处理输入文件耗尽的情况。
参考文献:J. Cryptology v 5 no 2, 1992 页 89-105
也可以在某些网站上找到,那里是我找到它的地方。
-David Honig
[email protected]
用法:
ULISCAN 文件名
输出到标准输出(stdout)
*/
#define L 8
#define V (1<<L)
#define Q (10*V)
#define K (100 *Q)
#define MAXSAMP (Q + K)
#include <stdio.h>
#include <math.h>
int main(argc, argv)
int argc;
char **argv;
{
FILE *fptr;
int i,j;
int b, c;
int table[V];
double sum = 0.0;
int iproduct = 1;
int run;
extern double log(/* double x */);
printf("Uliscan 21 Dec 98 \nL=%d %d %d \n", L, V, MAXSAMP);
if (argc < 2) {
printf("Usage: Uliscan filename\n");
exit(-1);
} else {
printf("Measuring file %s\n", argv[1]);
}
fptr = fopen(argv[1],"rb");
if (fptr == NULL) {
printf("Can't find %s\n", argv[1]);
exit(-1);
}
for (i = 0; i < V; i++) {
table[i] = 0;
}
for (i = 0; i < Q; i++) {
b = fgetc(fptr);
table[b] = i;
}
printf("Init done\n");
printf("Expected value for L=8 is 7.1836656\n");
run = 1;
while (run) {
sum = 0.0;
iproduct = 1;
if (run)
for (i = Q; run && i < Q + K; i++) {
j = i;
b = fgetc(fptr);
if (b < 0)
run = 0;
if (run) {
if (table[b] > j)
j += K;
sum += log((double)(j-table[b]));
table[b] = i;
}
}
if (!run)
printf("Premature end of file; read %d blocks.\n", i - Q);
sum = (sum/((double)(i - Q))) / log(2.0);
printf("%4.4f ", sum);
for (i = 0; i < (int)(sum*8.0 + 0.50); i++)
printf("-");
printf("\n");
/*重新填充初始表格 */
if (0) {
for (i = 0; i < Q; i++) {
b = fgetc(fptr);
if (b < 0) {
run = 0;
} else {
table[b] = i;
}
}
}
}
}% dmesg > /tmp/dmesg.out% tcpdump -c 4000 -s 10000 -w ipsecdemo.bin
% uliscan ipsecdemo.bin
Uliscan 21 Dec 98
L=8 256 258560
Measuring file ipsecdemo.bin
Init done
Expected value for L=8 is 7.1836656
6.9396 --------------------------------------------------------
6.6177 -----------------------------------------------------
6.4100 ---------------------------------------------------
2.1101 -----------------
2.0838 -----------------
2.0983 -----------------0 3 * * * root /usr/sbin/freebsd-update cron
# pkg install apache24# cd /usr/ports/www/apache24
# make install clean# cd /usr/ports/www/apache24
# make WITH_LDAP="YES" install clean# 启用 SSHD
sshd_enable="YES"
# 启用带 SSL 的 Apache
apache24_enable="YES"
apache24_flags="-DSSL"# service sshd start
# service apache24 start# service sshd onestart% ifconfig
em0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> mtu 1500
options=b<RXCSUM,TXCSUM,VLAN_MTU>
inet 10.10.10.100 netmask 0xffffff00 broadcast 10.10.10.255
ether 00:50:56:a7:70:b2
media: Ethernet autoselect (1000baseTX <full-duplex>)
status: active
em1: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> mtu 1500
options=b<RXCSUM,TXCSUM,VLAN_MTU>
inet 192.168.10.222 netmask 0xffffff00 broadcast 192.168.10.255
ether 00:50:56:a7:03:2b
media: Ethernet autoselect (1000baseTX <full-duplex>)
status: activehostname="server1.example.com"
ifconfig_em0="inet 10.10.10.100 netmask 255.255.255.0"
defaultrouter="10.10.10.1"hostname="server1.example.com"
ifconfig_em0="DHCP"pass in on $ext_if inet proto tcp from any to ($ext_if) port 22pass in on $ext_if proto tcp from any to any port = 22ipfw add allow tcp from any to me 22 in via $ext_if% sysctl net.inet.ip.forwarding
net.inet.ip.forwarding: 0% sysctl -a | moreproc /proc procfs rw,noauto 0 0# mount /proc 公司 家
10.246.38.1/24 -- 172.16.5.4 <--> 192.168.1.12 -- 10.0.0.5/24corp-gw# ifconfig gif0 create
corp-gw# ifconfig gif0 10.246.38.1 10.0.0.5
corp-gw# ifconfig gif0 tunnel 172.16.5.4 192.168.1.12home-gw# ifconfig gif0 create
home-gw# ifconfig gif0 10.0.0.5 10.246.38.1
home-gw# ifconfig gif0 tunnel 192.168.1.12 172.16.5.4gif0: flags=8051 mtu 1280
tunnel inet 172.16.5.4 --> 192.168.1.12
inet6 fe80::2e0:81ff:fe02:5881%gif0 prefixlen 64 scopeid 0x6
inet 10.246.38.1 --> 10.0.0.5 netmask 0xffffff00gif0: flags=8051 mtu 1280
tunnel inet 192.168.1.12 --> 172.16.5.4
inet 10.0.0.5 --> 10.246.38.1 netmask 0xffffff00
inet6 fe80::250:bfff:fe3a:c1f%gif0 prefixlen 64 scopeid 0x4home-gw# ping 10.0.0.5
PING 10.0.0.5 (10.0.0.5): 56 data bytes
64 bytes from 10.0.0.5: icmp_seq=0 ttl=64 time=42.786 ms
64 bytes from 10.0.0.5: icmp_seq=1 ttl=64 time=19.255 ms
64 bytes from 10.0.0.5: icmp_seq=2 ttl=64 time=20.440 ms
64 bytes from 10.0.0.5: icmp_seq=3 ttl=64 time=21.036 ms
--- 10.0.0.5 ping statistics ---
4 packets transmitted, 4 packets received, 0% packet loss
round-trip min/avg/max/stddev = 19.255/25.879/42.786/9.782 ms
corp-gw# ping 10.246.38.1
PING 10.246.38.1 (10.246.38.1): 56 data bytes
64 bytes from 10.246.38.1: icmp_seq=0 ttl=64 time=28.106 ms
64 bytes from 10.246.38.1: icmp_seq=1 ttl=64 time=42.917 ms
64 bytes from 10.246.38.1: icmp_seq=2 ttl=64 time=127.525 ms
64 bytes from 10.246.38.1: icmp_seq=3 ttl=64 time=119.896 ms
64 bytes from 10.246.38.1: icmp_seq=4 ttl=64 time=154.524 ms
--- 10.246.38.1 ping statistics ---
5 packets transmitted, 5 packets received, 0% packet loss
round-trip min/avg/max/stddev = 28.106/94.594/154.524/49.814 mscorp-gw# route add 10.0.0.0 10.0.0.5 255.255.255.0
corp-gw# route add net 10.0.0.0: gateway 10.0.0.5
home-gw# route add 10.246.38.0 10.246.38.1 255.255.255.0
home-gw# route add host 10.246.38.0: gateway 10.246.38.1corp-gw# ping -c 3 10.0.0.8
PING 10.0.0.8 (10.0.0.8): 56 data bytes
64 bytes from 10.0.0.8: icmp_seq=0 ttl=63 time=92.391 ms
64 bytes from 10.0.0.8: icmp_seq=1 ttl=63 time=21.870 ms
64 bytes from 10.0.0.8: icmp_seq=2 ttl=63 time=198.022 ms
--- 10.0.0.8 ping statistics ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max/stddev = 21.870/101.846/198.022/74.001 ms
home-gw# ping -c 3 10.246.38.107
PING 10.246.38.1 (10.246.38.107): 56 data bytes
64 bytes from 10.246.38.107: icmp_seq=0 ttl=64 time=53.491 ms
64 bytes from 10.246.38.107: icmp_seq=1 ttl=64 time=23.395 ms
64 bytes from 10.246.38.107: icmp_seq=2 ttl=64 time=23.865 ms
--- 10.246.38.107 ping statistics ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max/stddev = 21.145/31.721/53.491/12.179 mspath pre_shared_key "/usr/local/etc/racoon/psk.txt"; # 预共享密钥文件的位置
log debug; # 日志详细度设置:在测试和调试完成后设置为 'notify'
padding # 选项不可更改
{
maximum_length 20;
randomize off;
strict_check off;
exclusive_tail off;
}
timer # 定时选项,根据需要更改
{
counter 5;
interval 20 sec;
persend 1;
# natt_keepalive 15 sec;
phase1 30 sec;
phase2 15 sec;
}
listen # racoon 将监听的地址 [端口]
{
isakmp 172.16.5.4 [500];
isakmp_natt 172.16.5.4 [4500];
}
remote 192.168.1.12 [500]
{
exchange_mode main,aggressive;
doi ipsec_doi;
situation identity_only;
my_identifier address 172.16.5.4;
peers_identifier address 192.168.1.12;
lifetime time 8 hour;
passive off;
proposal_check obey;
# nat_traversal off;
generate_policy off;
proposal {
encryption_algorithm blowfish;
hash_algorithm md5;
authentication_method pre_shared_key;
lifetime time 30 sec;
dh_group 1;
}
}
sainfo (address 10.246.38.0/24 any address 10.0.0.0/24 any) # 地址 $network/$netmask $type 地址 $network/$netmask $type ( $type 可以是 any 或 esp)
{ # $network 必须是你要连接的两个内部网络。
pfs_group 1;
lifetime time 36000 sec;
encryption_algorithm blowfish,3des;
authentication_algorithm hmac_md5,hmac_sha1;
compression_algorithm deflate;
}flush;
spdflush;
# 到家用网络
spdadd 10.246.38.0/24 10.0.0.0/24 any -P out ipsec esp/tunnel/172.16.5.4-192.168.1.12/use;
spdadd 10.0.0.0/24 10.246.38.0/24 any -P in ipsec esp/tunnel/192.168.1.12-172.16.5.4/use;# /usr/local/sbin/racoon -F -f /usr/local/etc/racoon/racoon.conf -l /var/log/racoon.logcorp-gw# /usr/local/sbin/racoon -F -f /usr/local/etc/racoon/racoon.conf
Foreground mode.
2006-01-30 01:35:47: INFO: begin Identity Protection mode.
2006-01-30 01:35:48: INFO: received Vendor ID: KAME/racoon
2006-01-30 01:35:55: INFO: received Vendor ID: KAME/racoon
2006-01-30 01:36:04: INFO: ISAKMP-SA established 172.16.5.4[500]-192.168.1.12[500] spi:623b9b3bd2492452:7deab82d54ff704a
2006-01-30 01:36:05: INFO: initiate new phase 2 negotiation: 172.16.5.4[0]192.168.1.12[0]
2006-01-30 01:36:09: INFO: IPsec-SA established: ESP/Tunnel 192.168.1.12[0]->172.16.5.4[0] spi=28496098(0x1b2d0e2)
2006-01-30 01:36:09: INFO: IPsec-SA established: ESP/Tunnel 172.16.5.4[0]->192.168.1.12[0] spi=47784998(0x2d92426)
2006-01-30 01:36:13: INFO: respond new phase 2 negotiation: 172.16.5.4[0]192.168.1.12[0]
2006-01-30 01:36:18: INFO: IPsec-SA established: ESP/Tunnel 192.168.1.12[0]->172.16.5.4[0] spi=124397467(0x76a279b)
2006-01-30 01:36:18: INFO: IPsec-SA established: ESP/Tunnel 172.16.5.4[0]->192.168.1.12[0] spi=175852902(0xa7b4d66)corp-gw# tcpdump -i em0 host 172.16.5.4 and dst 192.168.1.1201:47:32.021683 IP corporatenetwork.com > 192.168.1.12.privatenetwork.com: ESP(spi=0x02acbf9f,seq=0xa)
01:47:33.022442 IP corporatenetwork.com > 192.168.1.12.privatenetwork.com: ESP(spi=0x02acbf9f,seq=0xb)
01:47:34.024218 IP corporatenetwork.com > 192.168.1.12.privatenetwork.com: ESP(spi=0x02acbf9f,seq=0xc)ipfw add 00201 allow log esp from any to any
ipfw add 00202 allow log ah from any to any
ipfw add 00203 allow log ipencap from any to any
ipfw add 00204 allow log udp from any 500 to anypass in quick proto esp from any to any
pass in quick proto ah from any to any
pass in quick proto ipencap from any to any
pass in quick proto udp from any port = 500 to any port = 500
pass in quick on gif0 from any to any
pass out quick proto esp from any to any
pass out quick proto ah from any to any
pass out quick proto ipencap from any to any
pass out quick proto udp from any port = 500 to any port = 500
pass out quick on gif0 from any to anyipsec_enable="YES"
ipsec_program="/usr/local/sbin/setkey"
ipsec_file="/usr/local/etc/racoon/setkey.conf" # 允许在启动时设置 spd 策略
racoon_enable="yes"/*
* Copyright (c) [年份] [你的名字]
*
* SPDX-License-Identifier: BSD-2-Clause
*//*
* Copyright (c) [年份] [your name]
*
* SPDX-License-Identifier: BSD-2-Clause
*//*
* Copyright (c) [年份] [你的名字]
*
* SPDX-License-Identifier: BSD-3-Clause
*//*
* Copyright (c) [年份] [版权持有者]
*
* SPDX-License-Identifier: ISC
*//*
* Copyright (c) [年份] [版权持有者]
*
* SPDX-License-Identifier: MIT
*/// SPDX-License-Identifier: GPL-2.0-only
// SPDX-License-Identifier: LGPL-2.1-or-later// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception// SPDX-License-Identifier: GPL-2.0 OR BSD-3-Clause// SPDX-License-Identifier: BSD-2-Clause AND MIT# cp -Rp /boot/GENERIC/* /boot/kernel# Device Mountpoint FStype Options Dump Pass#
/dev/mirror/swap none swap sw 0 0
/dev/mirror/root / ufs rw 1 1
/dev/mirror/usr /usr ufs rw 2 2
/dev/mirror/var /var ufs rw 2 2
/dev/cd0 /cdrom cd9660 ro,noauto 0 0geom_mirror_load="YES"
zfs_load="YES"# fetch http://mfsbsd.vx.sk/release/mfsbsd-2.1.tar.gz
# tar xvzf mfsbsd-2.1.tar.gz
# cd mfsbsd-2.1/mac_interfaces="ext1"
ifconfig_ext1_mac="00:00:00:00:00:00"
ifconfig_ext1="inet 192.168.0.2/24"defaultrouter="192.168.0.1"defaultrouter="192.168.0.1"
ifconfig_re0="inet 192.168.0.2/24"# mdconfig -a -t vnode -u 10 -f FreeBSD-10.1-RELEASE-amd64-disc1.iso
# mount_cd9660 /dev/md10 /cdrom# mkdir DIST
# tar -xvf /cdrom/usr/freebsd-dist/base.txz -C DIST
# tar -xvf /cdrom/usr/freebsd-dist/kernel.txz -C DIST# make BASE=DIST# scp disk.img [email protected]:.# dd if=/root/disk.img of=/dev/sda bs=1m# dd if=/dev/zero of=/dev/ad0 count=2# fdisk -BI /dev/ad0 ①
# fdisk -BI /dev/ad1
# bsdlabel -wB /dev/ad0s1 ②
# bsdlabel -wB /dev/ad1s1
# bsdlabel -e /dev/ad0s1 ③
# bsdlabel /dev/ad0s1 > /tmp/bsdlabel.txt && bsdlabel -R /dev/ad1s1 /tmp/bsdlabel.txt ④
# gmirror label root /dev/ad[01]s1a ⑤
# gmirror label var /dev/ad[01]s1d
# gmirror label usr /dev/ad[01]s1e
# gmirror label -F swap /dev/ad[01]s1b ⑥
# newfs /dev/mirror/root ⑦
# newfs /dev/mirror/var
# newfs /dev/mirror/usr# mount /dev/mirror/root /mnt
# mkdir /mnt/var /mnt/usr
# mount /dev/mirror/var /mnt/var
# mount /dev/mirror/usr /mnt/usr# chroot /mnt# zpool create tank mirror /dev/ad[01]s1f# zfs create tank/ports
# zfs create tank/src
# zfs set compression=gzip tank/ports
# zfs set compression=on tank/src
# zfs set mountpoint=/usr/ports tank/ports
# zfs set mountpoint=/usr/src tank/src# sysrc zfs_enable="YES"struct g_consumer*g_clone_bio()g_io_request()options INVARIANT_SUPPORT
options INVARIANTSoptions WITNESS_SUPPORT
options WITNESSmakeoptions DEBUG=-goptions KDB
options DDB
options KDB_TRACEdebug.debugger_on_panic=1kern.filedelay=5
kern.dirdelay=4
kern.metadelay=3dumpdev="/dev/ad0s4b"
dumpdir="/usr/corehw.physmem="256M"background_fsck="NO"SRCS=g_journal.c
KMOD=geom_journal
.include <bsd.kmod.mk>static MALLOC_DEFINE(M_GJOURNAL, "gjournal data", "GEOM_JOURNAL Data");verb [-options] geomname [other]% rsync -vaHz --delete rsync://ftp4.de.FreeBSD.org/FreeBSD/ /pub/FreeBSD/% cd website && env HUGO_baseURL="https://www.XX.freebsd.org/" make% pkg fetch -d -o /usr/local/mirror vim% pkg repo /usr/local/mirroralias su su -m# exit# /sbin/shutdown -h now# /sbin/shutdown -r now# /sbin/reboot# adduserLogin group is "jack". Invite jack into other groups: wheel# periodic daily
输出省略
# periodic weekly
输出省略
# periodic monthly
输出省略# cp rc.conf rc.conf.orig# mv rc.conf rc.conf.orig
# cp rc.conf.orig rc.conf# mv rc.conf rc.conf.myedit
# mv rc.conf.orig rc.conf# vi filename% find /usr -name "filename"# cp -R /cdrom/ports/comm/kermit /usr/local# make all installset prompt = "%h %t %\~ %# "# shutdown now# umount /usr /var# gjournal load# gjournal label ad0s1f ad0s1g
GEOM_JOURNAL: Journal 2948326772: ad0s1f contains data.
GEOM_JOURNAL: Journal 2948326772: ad0s1g contains journal.
# gjournal label ad0s1d ad0s1h
GEOM_JOURNAL: Journal 3193218002: ad0s1d contains data.
GEOM_JOURNAL: Journal 3193218002: ad0s1h contains journal.# gjournal label -f ad0s1d ad0s1h# tunefs -J enable -n disable ad0s1d.journal
tunefs: gjournal set
tunefs: soft updates cleared
# tunefs -J enable -n disable ad0s1f.journal
tunefs: gjournal set
tunefs: soft updates cleared# mount -o async /dev/ad0s1d.journal /var
# mount -o async /dev/ad0s1f.journal /usr/dev/ad0s1f.journal /usr ufs rw,async 2 2
/dev/ad0s1d.journal /var ufs rw,async 2 2geom_journal_load="YES"ad0: 76293MB XEC XE800JD-00HBC0 08.02D08 at ata0-master SATA150
GEOM_JOURNAL: Journal 2948326772: ad0s1g contains journal.
GEOM_JOURNAL: Journal 3193218002: ad0s1h contains journal.
GEOM_JOURNAL: Journal 3193218002: ad0s1d contains data.
GEOM_JOURNAL: Journal ad0s1d clean.
GEOM_JOURNAL: Journal 2948326772: ad0s1f contains data.
GEOM_JOURNAL: Journal ad0s1f clean.GEOM_JOURNAL: Journal ad0s1d consistent.# gjournal label ad1s1d# gjournal label -s 2G ad1s1d# newfs -J /dev/ad1s1d.journaloptions UFS_GJOURNAL # 注意:此项已包含在 GENERIC 中
options GEOM_JOURNAL # 需要你添加此项# cat /boot/loader.conf# gjournal load
GEOM_JOURNAL: Journal 2948326772: ad0s1g contains journal.
GEOM_JOURNAL: Journal 3193218002: ad0s1h contains journal.
GEOM_JOURNAL: Journal 3193218002: ad0s1d contains data.
GEOM_JOURNAL: Journal ad0s1d clean.
GEOM_JOURNAL: Journal 2948326772: ad0s1f contains data.
GEOM_JOURNAL: Journal ad0s1f clean.
# mount -a
# exit
(boot continues)# shutdown now# umount /usr /var# gjournal sync# gjournal stop ad0s1d.journal
# gjournal stop ad0s1f.journal# gjournal clear ad0s1d
# gjournal clear ad0s1f
# gjournal clear ad0s1g
# gjournal clear ad0s1h# tunefs -J disable -n enable ad0s1d
tunefs: gjournal cleared
tunefs: soft updates set
# tunefs -J disable -n enable ad0s1f
tunefs: gjournal cleared
tunefs: soft updates set# mount -o rw /dev/ad0s1d /var
# mount -o rw /dev/ad0s1f /usr/dev/ad0s1f /usr ufs rw 2 2
/dev/ad0s1d /var ufs rw 2 2vmstat 1 示例中,是否不会有一些页面错误是数据页面错误(从可执行文件到私有页面的 COW)?也就是说,我期望页面错误既有零填充的,也有程序数据的。还是你在暗示 FreeBSD 确实对程序数据进行了预 COW?pv_entry 和 vm_page 的细节(或者是否应该是 vm_pmap,如 McKusick、Bostic、Karel 和 Quarterman 在 4.4 版的第 180-181 页所述)?具体来说,什么样的操作/反应会要求扫描这些映射?A B C D A B C D A B C D A B C DCONF_BUILD# vi /etc/resolv.conf
[...]
# mount /cfg
# cp /etc/resolv.conf /cfg
# umount /cfg# git clone https://git.FreeBSD.org/src.git /usr/src# cd /usr/src/tools/tools/nanobsd ①
# sh nanobsd.sh ②
# cd /usr/obj/nanobsd.full ③
# dd if=_.disk.full of=/dev/da0 bs=64k ④# sh nanobsd.sh -c myconf.nanocust_foo () (
echo "bar=baz" > \
${NANO_WORLDDIR}/etc/foo
)
customize_cmd cust_foocust_etc_size () (
cd ${NANO_WORLDDIR}/conf
echo 30000 > default/etc/md_size
)
customize_cmd cust_etc_sizeNANO_NAME=custom
NANO_SRC=/usr/src
NANO_KERNEL=MYKERNEL
NANO_IMAGES=2
CONF_BUILD='
WITHOUT_KLDLOAD=YES
WITHOUT_NETGRAPH=YES
WITHOUT_PAM=YES
'
CONF_INSTALL='
WITHOUT_ACPI=YES
WITHOUT_BLUETOOTH=YES
WITHOUT_FORTRAN=YES
WITHOUT_HTML=YES
WITHOUT_LPR=YES
WITHOUT_MAN=YES
WITHOUT_SENDMAIL=YES
WITHOUT_SHAREDOCS=YES
WITHOUT_EXAMPLES=YES
WITHOUT_INSTALLLIB=YES
WITHOUT_CALENDAR=YES
WITHOUT_MISC=YES
WITHOUT_SHARE=YES
'
CONF_WORLD='
WITHOUT_BIND=YES
WITHOUT_MODULES=YES
WITHOUT_KERBEROS=YES
WITHOUT_GAMES=YES
WITHOUT_RESCUE=YES
WITHOUT_LOCALES=YES
WITHOUT_SYSCONS=YES
WITHOUT_INFO=YES
'
FlashDevice SanDisk 1G
cust_nobeastie() (
touch ${NANO_WORLDDIR}/boot/loader.conf
echo "beastie_disable=\"YES\"" >> ${NANO_WORLDDIR}/boot/loader.conf
)
customize_cmd cust_comconsole
customize_cmd cust_install_files
customize_cmd cust_allow_ssh_root
customize_cmd cust_nobeastie# ftp myhost
get _.disk.image "| sh updatep1"# ssh myhost cat _.disk.image.gz | zcat | sh updatep1myhost# nc -l 2222 < _.disk.image# nc myhost 2222 | sh updatep1% afmtodit -d DESC -e text.enc file.afm generate/textmap PS_font_name% afmtodit -d DESC -e text.enc 3of9.afm generate/textmap 3of9font8x8="iso-8x8" # 从 /usr/share/syscons/fonts/* 中获取 8x8 字体(或者 NO)。% vidcontrol VGA_80x60allscreens_flags="VGA_80x60" # 为所有虚拟屏幕设置此 vidcontrol 模式创建一个目录来存放字体文件
% mkdir -p /usr/local/share/fonts/type1
% cd /usr/local/share/fonts/type1
将 .pfa、.pfb 和 .afm 文件放在这里
也可以想要在这里保留 readme 文件和其他文档
% cp /cdrom/fonts/atm/showboat/showboat.pfb .
% cp /cdrom/fonts/atm/showboat/showboat.afm .
维护一个索引以交叉引用字体
% echo showboat - InfoMagic CICA, Dec 1994, /fonts/atm/showboat >>INDEX-bitstream-charter-medium-r-normal-xxx-0-0-0-0-p-0-iso8859-1
| | | | | | | | | | | | \ \
| | | | | \ \ \ \ \ \ \ +----+- 字符集
| | | | \ \ \ \ \ \ \ +- 平均宽度
| | | | \ \ \ \ \ \ +- 间距
| | | \ \ \ \ \ \ \ +- 垂直分辨率
| | | \ \ \ \ \ \ +- 水平分辨率
| | | \ \ \ \ +- 点数
| | | \ \ \ +- 像素
| | | \ \ \
字体厂商 字体家族 粗细 倾斜 宽度 额外风格% strings showboat.pfb | more
%!FontType1-1.0: Showboat 001.001
%%CreationDate: 1/15/91 5:16:03 PM
%%VMusage: 1024 45747
% Generated by Fontographer 3.1
% Showboat
1991 by David Rakowski. Alle Rechte Vorbehalten.
FontDirectory/Showboat known{/Showboat findfont dup/UniqueID known{dup
/UniqueID get 4962377 eq exch/FontType get 1 eq and}{pop false}ifelse
{save true}{false}ifelse}{false}ifelse
12 dict begin
/FontInfo 9 dict dup begin
/version (001.001) readonly def
/FullName (Showboat) readonly def
/FamilyName (Showboat) readonly def
/Weight (Medium) readonly def
/ItalicAngle 0 def
/isFixedPitch false def
/UnderlinePosition -106 def
/UnderlineThickness 16 def
/Notice (Showboat
1991 by David Rakowski. Alle Rechte Vorbehalten.) readonly def
end readonly def
/FontName /Showboat def
--stdin---type1-Showboat-medium-r-normal-decorative-0-0-0-0-p-0-iso8859-1...-normal-r-normal-...-p-...使字体对 X11 可访问
% cd /usr/X11R6/lib/X11/fonts/Type1
% ln -s /usr/local/share/fonts/type1/showboat.pfb .
编辑 fonts.dir 和 fonts.scale,添加描述字体的行,并在第一行中递增字体的数量。
% ex fonts.dir
:1p
25
:1c
26
.
:$a
showboat.pfb -type1-showboat-medium-r-normal-decorative-0-0-0-0-p-0-iso8859-1
.
:wq
fonts.scale 看起来与 fonts.dir 相同...
% cp fonts.dir fonts.scale
告诉 X11 发生了变化
% xset fp rehash
检查新字体
% xfontsel -pattern -type1-*将字体放入 Ghostscript 的字体目录
% cd /usr/local/share/ghostscript/fonts
% ln -s /usr/local/share/fonts/type1/showboat.pfb .
编辑 Fontmap 以便 Ghostscript 知道字体
% cd /usr/local/share/ghostscript/4.01
% ex Fontmap
:$a
/Showboat (showboat.pfb) ; % 来自 CICA /fonts/atm/showboat
.
:wq
使用 Ghostscript 检查字体
% gs prfont.ps
Aladdin Ghostscript 4.01 (1996-7-10)
Copyright (C) 1996 Aladdin Enterprises, Menlo Park, CA. All rights
reserved.
This software comes with NO WARRANTY: see the file PUBLIC for details.
从 /usr/local/share/ghostscript/fonts/tir_____.pfb 加载 Times-Roman 字体...
/1899520 581354 1300084 13826 0 完成。
GS>Showboat DoFont
从 /usr/local/share/ghostscript/fonts/showboat.pfb 加载 Showboat 字体...
1939688 565415 1300084 16901 0 完成。
>>showpage, 按 <return> 键继续<<
>>showpage, 按 <return> 键继续<<
>>showpage, 按 <return> 键继续<<
GS>quit% cp /usr/src/gnu/usr.bin/groff/afmtodit/afmtodit.pl /tmp
% ex /tmp/afmtodit.pl
:1c
#!/usr/bin/perl -P-
.
:wq许多 .afm 文件是 Mac 格式的,行由 ^M 分隔
我们需要将它们转换为 UNIX(R) 风格的 ^J 分隔行
% cd /tmp
% cat /usr/local/share/fonts/type1/showboat.afm |
tr '\015' '\012' >showboat.afm
现在创建 Groff 字体文件
% cd /usr/share/groff_font/devps
% /tmp/afmtodit.pl -d DESC -e text.enc /tmp/showboat.afm generate/textmap SHOWBOAT创建 .pfa 字体文件
% pfbtops /usr/local/share/fonts/type1/showboat.pfb >showboat.pfa获取内部字体名称
% fgrep internalname SHOWBOAT
internalname Showboat
告诉 Groff 字体需要被下载
% ex download
:$a
Showboat showboat.pfa
.
:wq% cd /tmp
% cat >example.t <<EOF
.sp 5
.ps 16
这是 Showboat 字体的示例:
.br
.ps 48
.vs (\n(.s+2)p
.sp
.ft SHOWBOAT
ABCDEFGHI
.br
JKLMNOPQR
.br
STUVWXYZ
.sp
.ps 16
.vs (\n(.s+2)p
.fp 5 SHOWBOAT
.ft R
要使用它作为段落的第一个字母,它会显示如下:
.sp 50p
\s(48\f5H\s0\fRere 是段落的第一个字母,使用 Showboat 字体。
需要额外的垂直空间来为较大的字母留出空间。
EOF
% groff -Tps example.t >example.ps
使用 Ghostscript/Ghostview
% ghostview example.ps
打印
% lpr -Ppostscript example.ps# make -f Makefile.sub afmtodit% gs -dNODISPLAY -q -- ttf2pf.ps TTF_name PS_font_name AFM_name% gs -dNODISPLAY -- ttf2pf.ps 3of9.ttf
Aladdin Ghostscript 5.10 (1997-11-23)
Copyright (C) 1997 Aladdin Enterprises, Menlo Park, CA. All rights reserved.
This software comes with NO WARRANTY: see the file PUBLIC for details.
Converting 3of9.ttf to 3of9.pfa and 3of9.afm.% gs -dNODISPLAY -- ttf2pf.ps 3of9.ttf A B
Aladdin Ghostscript 5.10 (1997-11-23)
Copyright (C) 1997 Aladdin Enterprises, Menlo Park, CA. All rights reserved.
This software comes with NO WARRANTY: see the file PUBLIC for details.
Converting 3of9.ttf to A.pfa and B.afm.ports)的一部分。这些应用程序大多数不是 FreeBSD 开发者编写的,FreeBSD 提供的只是安装该应用程序的框架。因此,只有当问题被认为是 FreeBSD 特有时,才应向 FreeBSD 开发者报告;否则,应报告给软件的原作者。standards。ssh-keygen -t dsa 来创建密钥对。此参数是可选的;当未定义 SSHKEY 时,将使用标准的密码身份验证作为备用身份验证方法。有关 SSH 和创建与使用密钥的详细信息,参见 ssh-keygen(1) 手册。obj-j<span> NUMBER</span>_http._tcp.update.myserver.com. IN SRV 0 2 80 host1.myserver.com.
IN SRV 0 1 80 host2.myserver.com.
IN SRV 0 0 80 host3.myserver.com.% git clone https://github.com/freebsd/freebsd-update-build.git freebsd-update-server# FreeBSD 更新构建的主配置文件。特定版本的配置数据位于
# 脚本树的下方。
# 用于获取发布版本的位置
export FTP=ftp://ftp2.freebsd.org/pub/FreeBSD/releases ①
# 主机平台
export HOSTPLATFORM=`uname -m`
# 用于 jail 内的主机名
export BUILDHOSTNAME=${HOSTPLATFORM}-builder.daemonology.net ②
# SSH 密钥的位置
export SSHKEY=/root/.ssh/id_dsa ③
# 上传文件的 SSH 账户
[email protected] ④
# 上传文件的目录
MASTERDIR=update-master.freebsd.org ⑤% mkdir -p /usr/local/freebsd-update-server/scripts/7.2-RELEASE/amd64# RELEASE disc1.iso 镜像的 SHA256 哈希值。
export RELH=1ea1f6f652d7c5f5eab7ef9f8edbed50cb664b08ed761850f95f48e86cc71ef5 ①
# 系统、源代码和内核的组件
export WORLDPARTS="base catpages dict doc games info manpages proflibs lib32"
export SOURCEPARTS="base bin contrib crypto etc games gnu include krb5 \
lib libexec release rescue sbin secure share sys tools \
ubin usbin cddl"
export KERNELPARTS="generic"
# 生命周期结束日期
export EOL=1275289200 ②% date -j -f '%Y%m%d-%H%M%S' '20090401-000000' '+%s'# sh scripts/make.sh
cc -O2 -fno-strict-aliasing -pipe findstamps.c -o findstamps
findstamps.c: In function 'usage':
findstamps.c:45: warning: incompatible implicit declaration of built-in function 'exit'
cc -O2 -fno-strict-aliasing -pipe unstamp.c -o unstamp
install findstamps ../bin
install unstamp ../bin
rm -f findstamps unstamp
Generating RSA private key, 4096 bit long modulus
................................................................................++
...................++
e is 65537 (0x10001)
Public key fingerprint:
27ef53e48dc869eea6c3136091cc6ab8589f967559824779e855d58a2294de9e
Encrypting signing key for root
enter aes-256-cbc encryption password:
Verifying - enter aes-256-cbc encryption password:# cd /usr/local/freebsd-update-server
# sh scripts/init.sh amd64 7.2-RELEASE# sh scripts/init.sh amd64 7.2-RELEASE
Mon Aug 24 16:04:36 PDT 2009 Starting fetch for FreeBSD/amd64 7.2-RELEASE
/usr/local/freebsd-update-server/work/7.2-RELE100 of 588 MB 359 kBps 00m00s
Mon Aug 24 16:32:38 PDT 2009 Verifying disc1 hash for FreeBSD/amd64 7.2-RELEASE
Mon Aug 24 16:32:44 PDT 2009 Extracting components for FreeBSD/amd64 7.2-RELEASE
Mon Aug 24 16:34:05 PDT 2009 Constructing world+src image for FreeBSD/amd64 7.2-RELEASE
Mon Aug 24 16:35:57 PDT 2009 Extracting world+src for FreeBSD/amd64 7.2-RELEASE
Mon Aug 24 23:36:24 UTC 2009 Building world for FreeBSD/amd64 7.2-RELEASE
Tue Aug 25 00:31:29 UTC 2009 Distributing world for FreeBSD/amd64 7.2-RELEASE
Tue Aug 25 00:32:36 UTC 2009 Building and distributing kernels for FreeBSD/amd64 7.2-RELEASE
Tue Aug 25 00:44:44 UTC 2009 Constructing world components for FreeBSD/amd64 7.2-RELEASE
Tue Aug 25 00:44:56 UTC 2009 Distributing source for FreeBSD/amd64 7.2-RELEASE
Mon Aug 24 17:46:18 PDT 2009 Moving components into staging area for FreeBSD/amd64 7.2-RELEASE
Mon Aug 24 17:46:33 PDT 2009 Identifying extra documentation for FreeBSD/amd64 7.2-RELEASE
Mon Aug 24 17:47:13 PDT 2009 Extracting extra docs for FreeBSD/amd64 7.2-RELEASE
Mon Aug 24 17:47:18 PDT 2009 Indexing release for FreeBSD/amd64 7.2-RELEASE
Mon Aug 24 17:50:44 PDT 2009 Indexing world0 for FreeBSD/amd64 7.2-RELEASE
Files built but not released:
Files released but not built:
Files which differ by more than contents:
Files which differ between release and build:
kernel|generic|/GENERIC/hptrr.ko
kernel|generic|/GENERIC/kernel
src|sys|/sys/conf/newvers.sh
world|base|/boot/loader
world|base|/boot/pxeboot
world|base|/etc/mail/freebsd.cf
world|base|/etc/mail/freebsd.submit.cf
world|base|/etc/mail/sendmail.cf
world|base|/etc/mail/submit.cf
world|base|/lib/libcrypto.so.5
world|base|/usr/bin/ntpq
world|base|/usr/lib/libalias.a
world|base|/usr/lib/libalias_cuseeme.a
world|base|/usr/lib/libalias_dummy.a
world|base|/usr/lib/libalias_ftp.a
...Mon Aug 24 17:54:07 PDT 2009 Extracting world+src for FreeBSD/amd64 7.2-RELEASE
Wed Sep 29 00:54:34 UTC 2010 Building world for FreeBSD/amd64 7.2-RELEASE
Wed Sep 29 01:49:42 UTC 2010 Distributing world for FreeBSD/amd64 7.2-RELEASE
Wed Sep 29 01:50:50 UTC 2010 Building and distributing kernels for FreeBSD/amd64 7.2-RELEASE
Wed Sep 29 02:02:56 UTC 2010 Constructing world components for FreeBSD/amd64 7.2-RELEASE
Wed Sep 29 02:03:08 UTC 2010 Distributing source for FreeBSD/amd64 7.2-RELEASE
Tue Sep 28 19:04:31 PDT 2010 Moving components into staging area for FreeBSD/amd64 7.2-RELEASE
Mon Aug 24 19:04:46 PDT 2009 Extracting extra docs for FreeBSD/amd64 7.2-RELEASE
Mon Aug 24 19:04:51 PDT 2009 Indexing world1 for FreeBSD/amd64 7.2-RELEASE
Mon Aug 24 19:08:04 PDT 2009 Locating build stamps for FreeBSD/amd64 7.2-RELEASE
Mon Aug 24 19:10:19 PDT 2009 Cleaning staging area for FreeBSD/amd64 7.2-RELEASE
Mon Aug 24 19:10:19 PDT 2009 Preparing to copy files into staging area for FreeBSD/amd64 7.2-RELEASE
Mon Aug 24 19:10:20 PDT 2009 Copying data files into staging area for FreeBSD/amd64 7.2-RELEASE
Mon Aug 24 12:16:57 PDT 2009 Copying metadata files into staging area for FreeBSD/amd64 7.2-RELEASE
Mon Aug 24 12:16:59 PDT 2009 Constructing metadata index and tag for FreeBSD/amd64 7.2-RELEASE
Files found which include build stamps:
kernel|generic|/GENERIC/hptrr.ko
kernel|generic|/GENERIC/kernel
world|base|/boot/loader
world|base|/boot/pxeboot
world|base|/etc/mail/freebsd.cf
world|base|/etc/mail/freebsd.submit.cf
world|base|/etc/mail/sendmail.cf
world|base|/etc/mail/submit.cf
world|base|/lib/libcrypto.so.5
world|base|/usr/bin/ntpq
world|base|/usr/include/osreldate.h
world|base|/usr/lib/libalias.a
world|base|/usr/lib/libalias_cuseeme.a
world|base|/usr/lib/libalias_dummy.a
world|base|/usr/lib/libalias_ftp.a
...Values of build stamps, excluding library archive headers:
v1.2 (Aug 25 2009 00:40:36)
v1.2 (Aug 25 2009 00:38:22)
@()FreeBSD 7.2-RELEASE 0: Tue Aug 25 00:38:29 UTC 2009
FreeBSD 7.2-RELEASE 0: Tue Aug 25 00:38:29 UTC 2009
[email protected]:/usr/obj/usr/src/sys/GENERIC
7.2-RELEASE
Mon Aug 24 23:55:25 UTC 2009
Mon Aug 24 23:55:25 UTC 2009
built by [email protected] on Tue Aug 25 00:16:15 UTC 2009
built by [email protected] on Tue Aug 25 00:16:15 UTC 2009
built by [email protected] on Tue Aug 25 00:16:15 UTC 2009
built by [email protected] on Tue Aug 25 00:16:15 UTC 2009
Mon Aug 24 23:46:47 UTC 2009
ntpq 4.2.4p5-a Mon Aug 24 23:55:53 UTC 2009 (1)
* Copyright (c) 1992-2009 The FreeBSD Project.
Mon Aug 24 23:46:47 UTC 2009
Mon Aug 24 23:55:40 UTC 2009
Aug 25 2009
ntpd 4.2.4p5-a Mon Aug 24 23:55:52 UTC 2009 (1)
ntpdate 4.2.4p5-a Mon Aug 24 23:55:53 UTC 2009 (1)
ntpdc 4.2.4p5-a Mon Aug 24 23:55:53 UTC 2009 (1)
Tue Aug 25 00:21:21 UTC 2009
Tue Aug 25 00:21:21 UTC 2009
Tue Aug 25 00:21:21 UTC 2009
Mon Aug 24 23:46:47 UTC 2009
FreeBSD/amd64 7.2-RELEASE initialization build complete. Please
review the list of build stamps printed above to confirm that
they look sensible, then run
sh -e approve.sh amd64 7.2-RELEASE
to sign the release.# cd /usr/local/freebsd-update-server
# sh scripts/mountkey.sh# sh -e scripts/approve.sh amd64 7.2-RELEASE
Wed Aug 26 12:50:06 PDT 2009 Signing build for FreeBSD/amd64 7.2-RELEASE
Wed Aug 26 12:50:06 PDT 2009 Copying files to patch source directories for FreeBSD/amd64 7.2-RELEASE
Wed Aug 26 12:50:06 PDT 2009 Copying files to upload staging area for FreeBSD/amd64 7.2-RELEASE
Wed Aug 26 12:50:07 PDT 2009 Updating databases for FreeBSD/amd64 7.2-RELEASE
Wed Aug 26 12:50:07 PDT 2009 Cleaning staging area for FreeBSD/amd64 7.2-RELEASE# cd /usr/local/freebsd-update-server
# sh scripts/upload.sh amd64 7.2-RELEASE# cd /usr/local/freebsd-update-server/pub/7.2-RELEASE/amd64
# touch -t 200801010101.01 uploaded% mkdir -p /usr/local/freebsd-update-server/patches/7.1-RELEASE/
% cd /usr/local/freebsd-update-server/patches/7.1-RELEASE% cd /usr/local/freebsd-update-server/patches/7.1-RELEASE/; mv bind.patch 7-SA-09:12.bind# cd /usr/local/freebsd-update-server
# sh scripts/diff.sh amd64 7.1-RELEASE 7# sh -e scripts/diff.sh amd64 7.1-RELEASE 7
Wed Aug 26 10:09:59 PDT 2009 Extracting world+src for FreeBSD/amd64 7.1-RELEASE-p7
Wed Aug 26 17:10:25 UTC 2009 Building world for FreeBSD/amd64 7.1-RELEASE-p7
Wed Aug 26 18:05:11 UTC 2009 Distributing world for FreeBSD/amd64 7.1-RELEASE-p7
Wed Aug 26 18:06:16 UTC 2009 Building and distributing kernels for FreeBSD/amd64 7.1-RELEASE-p7
Wed Aug 26 18:17:50 UTC 2009 Constructing world components for FreeBSD/amd64 7.1-RELEASE-p7
Wed Aug 26 18:18:02 UTC 2009 Distributing source for FreeBSD/amd64 7.1-RELEASE-p7
Wed Aug 26 11:19:23 PDT 2009 Moving components into staging area for FreeBSD/amd64 7.1-RELEASE-p7
Wed Aug 26 11:19:37 PDT 2009 Extracting extra docs for FreeBSD/amd64 7.1-RELEASE-p7
Wed Aug 26 11:19:42 PDT 2009 Indexing world0 for FreeBSD/amd64 7.1-RELEASE-p7
Wed Aug 26 11:23:02 PDT 2009 Extracting world+src for FreeBSD/amd64 7.1-RELEASE-p7
Thu Sep 30 18:23:29 UTC 2010 Building world for FreeBSD/amd64 7.1-RELEASE-p7
Thu Sep 30 19:18:15 UTC 2010 Distributing world for FreeBSD/amd64 7.1-RELEASE-p7
Thu Sep 30 19:19:18 UTC 2010 Building and distributing kernels for FreeBSD/amd64 7.1-RELEASE-p7
Thu Sep 30 19:30:52 UTC 2010 Constructing world components for FreeBSD/amd64 7.1-RELEASE-p7
Thu Sep 30 19:31:03 UTC 2010 Distributing source for FreeBSD/amd64 7.1-RELEASE-p7
Thu Sep 30 12:32:25 PDT 2010 Moving components into staging area for FreeBSD/amd64 7.1-RELEASE-p7
Wed Aug 26 12:32:39 PDT 2009 Extracting extra docs for FreeBSD/amd64 7.1-RELEASE-p7
Wed Aug 26 12:32:43 PDT 2009 Indexing world1 for FreeBSD/amd64 7.1-RELEASE-p7
Wed Aug 26 12:35:54 PDT 2009 Locating build stamps for FreeBSD/amd64 7.1-RELEASE-p7
Wed Aug 26 12:36:58 PDT 2009 Reverting changes due to build stamps for FreeBSD/amd64 7.1-RELEASE-p7
Wed Aug 26 12:37:14 PDT 2009 Cleaning staging area for FreeBSD/amd64 7.1-RELEASE-p7
Wed Aug 26 12:37:14 PDT 2009 Preparing to copy files into staging area for FreeBSD/amd64 7.1-RELEASE-p7
Wed Aug 26 12:37:15 PDT 2009 Copying data files into staging area for FreeBSD/amd64 7.1-RELEASE-p7
Wed Aug 26 12:43:23 PDT 2009 Copying metadata files into staging area for FreeBSD/amd64 7.1-RELEASE-p7
Wed Aug 26 12:43:25 PDT 2009 Constructing metadata index and tag for FreeBSD/amd64 7.1-RELEASE-p7
...
Files found which include build stamps:
kernel|generic|/GENERIC/hptrr.ko
kernel|generic|/GENERIC/kernel
world|base|/boot/loader
world|base|/boot/pxeboot
world|base|/etc/mail/freebsd.cf
world|base|/etc/mail/freebsd.submit.cf
world|base|/etc/mail/sendmail.cf
world|base|/etc/mail/submit.cf
world|base|/lib/libcrypto.so.5
world|base|/usr/bin/ntpq
world|base|/usr/include/osreldate.h
world|base|/usr/lib/libalias.a
world|base|/usr/lib/libalias_cuseeme.a
world|base|/usr/lib/libalias_dummy.a
world|base|/usr/lib/libalias_ftp.a
...
Values of build stamps, excluding library archive headers:
v1.2 (Aug 26 2009 18:13:46)
v1.2 (Aug 26 2009 18:11:44)
@()FreeBSD 7.1-RELEASE-p7 0: Wed Aug 26 18:11:50 UTC 2009
FreeBSD 7.1-RELEASE-p7 0: Wed Aug 26 18:11:50 UTC 2009
[email protected]:/usr/obj/usr/src/sys/GENERIC
7.1-RELEASE-p7
Wed Aug 26 17:29:15 UTC 2009
Wed Aug 26 17:29:15 UTC 2009
built by [email protected] on Wed Aug 26 17:49:58 UTC 2009
built by [email protected] on Wed Aug 26 17:49:58 UTC 2009
built by [email protected] on Wed Aug 26 17:49:58 UTC 2009
built by [email protected] on Wed Aug 26 17:49:58 UTC 2009
Wed Aug 26 17:20:39 UTC 2009
ntpq 4.2.4p5-a Wed Aug 26 17:29:42 UTC 2009 (1)
* Copyright (c) 1992-2009 The FreeBSD Project.
Wed Aug 26 17:20:39 UTC 2009
Wed Aug 26 17:29:30 UTC 2009
Aug 26 2009
ntpd 4.2.4p5-a Wed Aug 26 17:29:41 UTC 2009 (1)
ntpdate 4.2.4p5-a Wed Aug 26 17:29:42 UTC 2009 (1)
ntpdc 4.2.4p5-a Wed Aug 26 17:29:42 UTC 2009 (1)
Wed Aug 26 17:55:02 UTC 2009
Wed Aug 26 17:55:02 UTC 2009
Wed Aug 26 17:55:02 UTC 2009
Wed Aug 26 17:20:39 UTC 2009
...New updates:
kernel|generic|/GENERIC/kernel.symbols|f|0|0|0555|0|7c8dc176763f96ced0a57fc04e7c1b8d793f27e006dd13e0b499e1474ac47e10|
kernel|generic|/GENERIC/kernel|f|0|0|0555|0|33197e8cf15bbbac263d17f39c153c9d489348c2c534f7ca1120a1183dec67b1|
kernel|generic|/|d|0|0|0755|0||
src|base|/|d|0|0|0755|0||
src|bin|/|d|0|0|0755|0||
src|cddl|/|d|0|0|0755|0||
src|contrib|/contrib/bind9/bin/named/update.c|f|0|10000|0644|0|4d434abf0983df9bc47435670d307fa882ef4b348ed8ca90928d250f42ea0757|
src|contrib|/contrib/bind9/lib/dns/openssldsa_link.c|f|0|10000|0644|0|c6805c39f3da2a06dd3f163f26c314a4692d4cd9a2d929c0acc88d736324f550|
src|contrib|/contrib/bind9/lib/dns/opensslrsa_link.c|f|0|10000|0644|0|fa0f7417ee9da42cc8d0fd96ad24e7a34125e05b5ae075bd6e3238f1c022a712|
...
FreeBSD/amd64 7.1-RELEASE update build complete. Please review
the list of build stamps printed above and the list of updated
files to confirm that they look sensible, then run
sh -e approve.sh amd64 7.1-RELEASE
to sign the build.# sh -e scripts/approve.sh amd64 7.1-RELEASE
Wed Aug 26 12:50:06 PDT 2009 Signing build for FreeBSD/amd64 7.1-RELEASE
Wed Aug 26 12:50:06 PDT 2009 Copying files to patch source directories for FreeBSD/amd64 7.1-RELEASE
Wed Aug 26 12:50:06 PDT 2009 Copying files to upload staging area for FreeBSD/amd64 7.1-RELEASE
Wed Aug 26 12:50:07 PDT 2009 Updating databases for FreeBSD/amd64 7.1-RELEASE
Wed Aug 26 12:50:07 PDT 2009 Cleaning staging area for FreeBSD/amd64 7.1-RELEASE
The FreeBSD/amd64 7.1-RELEASE update build has been signed and is
ready to be uploaded. Remember to run
sh -e umountkey.sh
to unmount the decrypted key once you have finished signing all
the new builds.# 比较 ${WORKDIR}/release 和 ${WORKDIR}/$1,找出缺少的世界或文档子组件,并
# 将其打包。
findextradocs () {
}
# 将额外的文档添加到 ${WORKDIR}/$1
addextradocs () {
}# 构建世界
log "Building world"
cd /usr/src &&
make -j 2 ${COMPATFLAGS} buildworld 2>&1
# 分发世界
log "Distributing world"
cd /usr/src/release &&
make -j 2 obj &&
make ${COMPATFLAGS} release.1 release.2 2>&1# svn log -v $FSVN/stable/9# svn cp $FSVN/stable/9@REVISION $FSVN/releng/9.2# svn co $FSVN/releng/9.2 src# svn cp $FSVN/releng/9.2 $FSVN/release/9.2.0# cd /usr/src/release
# sh generate-release.sh release/9.2.0 /local3/release/stage/cdrom# find . -type f | sed -e 's/^\.\///' | sort > filename.txt# sysctl security.bsd.see_other_uids=0# cd /usr/ports/net/openldap26-server
# make install cleansecurity ssf=128
TLSCertificateFile /path/to/your/cert.crt
TLSCertificateKeyFile /path/to/your/cert.key
TLSCACertificateFile /path/to/your/cacert.crt% openssl genrsa -out cert.key 1024
Generating RSA private key, 1024 bit long modulus
....................++++++
...++++++
e is 65537 (0x10001)
% openssl req -new -key cert.key -out cert.csr% openssl x509 -req -in cert.csr -days 365 -signkey cert.key -out cert.crt
Signature ok
subject=/C=AU/ST=Some-State/O=Internet Widgits Pty Ltd
Getting Private keyslapd_enable="YES"% sockstat -4 -p 389
ldap slapd 3261 7 tcp4 *:389 *:*base dc=example,dc=org
uri ldap://server.example.org/
ssl start_tls
tls_cacert /path/to/your/cacert.crtdn: ou=people,dc=example,dc=org
objectClass: top
objectClass: organizationalUnit
ou: peopledn: uid=tuser,ou=people,dc=example,dc=org
objectClass: person
objectClass: posixAccount
objectClass: shadowAccount
objectClass: top
uidNumber: 10000
gidNumber: 10000
homeDirectory: /home/tuser
loginShell: /bin/csh
uid: tuser
cn: tuserdn: ou=groups,dc=example,dc=org
objectClass: top
objectClass: organizationalUnit
ou: groups
dn: cn=tuser,ou=groups,dc=example,dc=org
objectClass: posixGroup
objectClass: top
gidNumber: 10000
cn: tuserpam_login_attribute uid% getent passwd username# ln -s /usr/local/bin/bash /bin/bashauth sufficient /usr/local/lib/pam_ldap.so no_warnpam_groupdn cn=servername,ou=accessgroups,dc=example,dc=orgmemberUid: uid=someuser,ou=people,dc=example,dc=orgauth required pam_nologin.so no_warn
auth sufficient pam_opie.so no_warn no_fake_prompts
auth requisite pam_opieaccess.so no_warn allow_local
auth sufficient /usr/local/lib/pam_ldap.so no_warn
auth required pam_unix.so no_warn try_first_pass
account required pam_login_access.so
account required /usr/local/lib/pam_ldap.so no_warn ignore_authinfo_unavail ignore_unknown_usergroup: compat
passwd: compatgroup: files ldap
passwd: files ldap#!/bin/sh
stty -echo
read -p "Old Password: " oldp; echo
read -p "New Password: " np1; echo
read -p "Retype New Password: " np2; echo
stty echo
if [ "$np1" != "$np2" ]; then
echo "Passwords do not match."
exit 1
fi
ldappasswd -D uid="$USER",ou=people,dc=example,dc=org \
-w "$oldp" \
-a "$oldp" \
-s "$np1"require 'ldap'
require 'base64'
require 'digest'
require 'password' # ruby-password
ldap_server = "ldap.example.org"
luser = "uid=#{ENV['USER']},ou=people,dc=example,dc=org"
# 获取新密码、进行检查并生成带盐的哈希值
def get_password
pwd1 = Password.get("New Password: ")
pwd2 = Password.get("Retype New Password: ")
raise if pwd1 != pwd2
pwd1.check # 检查密码强度
salt = rand.to_s.gsub(/0\./, '')
pass = pwd1.to_s
hash = "{SSHA}"+Base64.encode64(Digest::SHA1.digest("#{pass}#{salt}")+salt).chomp!
return hash
end
oldp = Password.get("Old Password: ")
newp = get_password
# 我们将直接替换旧密码。能够成功绑定说明我们要么知道旧密码,要么有管理员权限。
replace = LDAP::Mod.new(LDAP::LDAP_MOD_REPLACE | LDAP::LDAP_MOD_BVALUES,
"userPassword",
[newp])
conn = LDAP::SSLConn.new(ldap_server, 389, true)
conn.set_option(LDAP::LDAP_OPT_PROTOCOL_VERSION, 3)
conn.bind(luser, oldp)
conn.modify(luser, [replace])access to dn.subtree="ou=people,dc=example,dc=org"
attrs=userPassword
by self write
by anonymous auth
by * none
access to *
by self write
by * readaccess to dn.subtree="ou=people,dc=example,dc=org"
attrs=userPassword
by self write
by anonymous auth
by * none
access to attrs=homeDirectory,uidNumber,gidNumber
by * read
access to *
by self write
by * readdn: cn=homemanagement,dc=example,dc=org
objectClass: top
objectClass: posixGroup
cn: homemanagement
gidNumber: 121 # posixGroup 所需
memberUid: uid=tuser,ou=people,dc=example,dc=org
memberUid: uid=user2,ou=people,dc=example,dc=orgaccess to dn.subtree="ou=people,dc=example,dc=org"
attr=homeDirectory
by dn="cn=homemanagement,dc=example,dc=org"
dnattr=memberUid write% openssl genrsa -out root.key 1024
% openssl req -new -key root.key -out root.csr
% openssl x509 -req -days 1024 -in root.csr -signkey root.key -out root.crt% openssl x509 -req -days 1024 \
-in ldap-server-one.csr -CA root.crt -CAkey root.key \
-out ldap-server-one.crt% diff -u oldfile newfile% diff -u -r -N olddir newdirThe FreeBSD Foundation
3980 Broadway Street
STE #103-107
Boulder CO 80304
USA
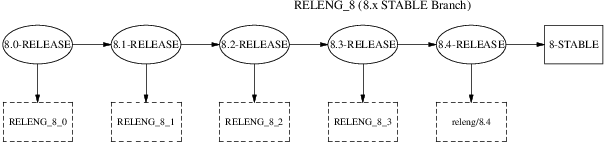
BETA 或 RC 阶段的网站更改BETA、RC 和最终 RELEASE 期间的 Ports 更改stable/ 分支发布stable 分支代码冻结准备BETA 构建ftp-master 上的临时存储目录
所有构建完成以后,/snap/ftp/snapshots 或发布版本的 /snap/ftp/releases 将通过 rsync 被 ftp-master 拉取到 /archive/tmp/snapshots 或 /archive/tmp/releases。% git checkout -b stable/13#ifndef MALLOC_PRODUCTION
#define MALLOC_PRODUCTION
#endif% git checkout -b releng/13.0% git add .
% git commit# /bin/sh /usr/src/release/release.sh# release.sh 配置用于 powerpc/powerpc64
CHROOTDIR="/scratch-powerpc64"
TARGET="powerpc"
TARGET_ARCH="powerpc64"
KERNEL="GENERIC64"# /bin/sh /usr/src/release/release.sh -c $HOME/release.conf% git tag release/13.0.0# make -C /usr/src/release -f Makefile.mirrors EVERYTHINGISFINE=1 ftp-stage% cd /archive/tmp/snapshots
% pax -r -w -l . /archive/pub/FreeBSD/snapshots
% /usr/local/bin/rsync -avH /archive/tmp/snapshots/* /archive/pub/FreeBSD/snapshots/# fsck -n /dev/devnameadrive a device /dev/da3h
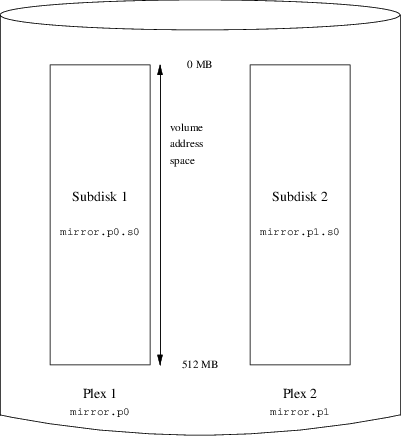
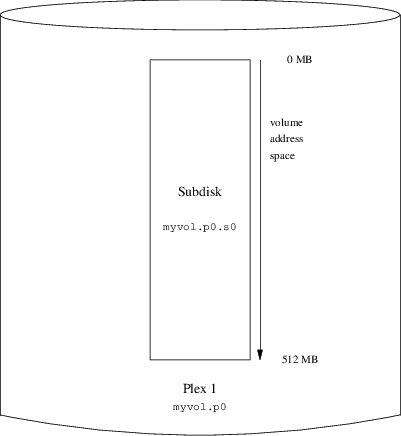
volume myvol
plex org concat
sd length 512m drive a# gvinum -> create config1
Configuration summary
Drives: 1 (4 configured)
Volumes: 1 (4 configured)
Plexes: 1 (8 configured)
Subdisks: 1 (16 configured)
D a State: up Device /dev/da3h Avail: 2061/2573 MB (80%)
V myvol State: up Plexes: 1 Size: 512 MB
P myvol.p0 C State: up Subdisks: 1 Size: 512 MB
S myvol.p0.s0 State: up PO: 0 B Size: 512 MBdrive b device /dev/da4h
volume mirror
plex org concat
sd length 512m drive a
plex org concat
sd length 512m drive bDrives: 2 (4 configured)
Volumes: 2 (4 configured)
Plexes: 3 (8 configured)
Subdisks: 3 (16 configured)
D a State: up Device /dev/da3h Avail: 1549/2573 MB (60%)
D b State: up Device /dev/da4h Avail: 2061/2573 MB (80%)
V myvol State: up Plexes: 1 Size: 512 MB
V mirror State: up Plexes: 2 Size: 512 MB
P myvol.p0 C State: up Subdisks: 1 Size: 512 MB
P mirror.p0 C State: up Subdisks: 1 Size: 512 MB
P mirror.p1 C State: initializing Subdisks: 1 Size: 512 MB
S myvol.p0.s0 State: up PO: 0 B Size: 512 MB
S mirror.p0.s0 State: up PO: 0 B Size: 512 MB
S mirror.p1.s0 State: empty PO: 0 B Size: 512 MBdrive c device /dev/da5h
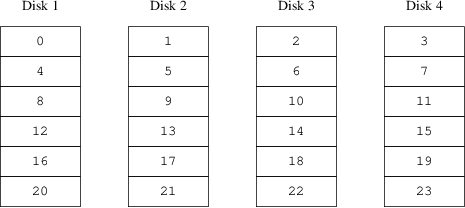
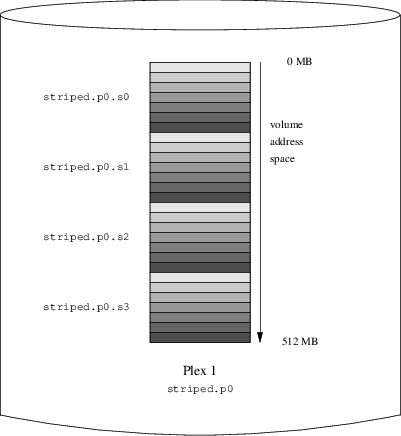
drive d device /dev/da6h
volume stripe
plex org striped 512k
sd length 128m drive a
sd length 128m drive b
sd length 128m drive c
sd length 128m drive dDrives: 4 (4 configured)
Volumes: 3 (4 configured)
Plexes: 4 (8 configured)
Subdisks: 7 (16 configured)
D a State: up Device /dev/da3h Avail: 1421/2573 MB (55%)
D b State: up Device /dev/da4h Avail: 1933/2573 MB (75%)
D c State: up Device /dev/da5h Avail: 2445/2573 MB (95%)
D d State: up Device /dev/da6h Avail: 2445/2573 MB (95%)
V myvol State: up Plexes: 1 Size: 512 MB
V mirror State: up Plexes: 2 Size: 512 MB
V striped State: up Plexes: 1 Size: 512 MB
P myvol.p0 C State: up Subdisks: 1 Size: 512 MB
P mirror.p0 C State: up Subdisks: 1 Size: 512 MB
P mirror.p1 C State: initializing Subdisks: 1 Size: 512 MB
P striped.p1 State: up Subdisks: 1 Size: 512 MB
S myvol.p0.s0 State: up PO: 0 B Size: 512 MB
S mirror.p0.s0 State: up PO: 0 B Size: 512 MB
S mirror.p1.s0 State: empty PO: 0 B Size: 512 MB
S striped.p0.s0 State: up PO: 0 B Size: 128 MB
S striped.p0.s1 State: up PO: 512 kB Size: 128 MB
S striped.p0.s2 State: up PO: 1024 kB Size: 128 MB
S striped.p0.s3 State: up PO: 1536 kB Size: 128 MBvolume raid10
plex org striped 512k
sd length 102480k drive a
sd length 102480k drive b
sd length 102480k drive c
sd length 102480k drive d
sd length 102480k drive e
plex org striped 512k
sd length 102480k drive c
sd length 102480k drive d
sd length 102480k drive e
sd length 102480k drive a
sd length 102480k drive bdrive drive1 device /dev/sd1h
drive drive2 device /dev/sd2h
drive drive3 device /dev/sd3h
drive drive4 device /dev/sd4h
volume s64 setupstate
plex org striped 64k
sd length 100m drive drive1
sd length 100m drive drive2
sd length 100m drive drive3
sd length 100m drive drive4drwxr-xr-x 2 root wheel 512 Apr 13
16:46 plex
crwxr-xr-- 1 root wheel 91, 2 Apr 13 16:46 s64
drwxr-xr-x 2 root wheel 512 Apr 13 16:46 sd
/dev/vinum/plex:
total 0
crwxr-xr-- 1 root wheel 25, 0x10000002 Apr 13 16:46 s64.p0
/dev/vinum/sd:
total 0
crwxr-xr-- 1 root wheel 91, 0x20000002 Apr 13 16:46 s64.p0.s0
crwxr-xr-- 1 root wheel 91, 0x20100002 Apr 13 16:46 s64.p0.s1
crwxr-xr-- 1 root wheel 91, 0x20200002 Apr 13 16:46 s64.p0.s2
crwxr-xr-- 1 root wheel 91, 0x20300002 Apr 13 16:46 s64.p0.s3# newfs /dev/gvinum/concatvolume myvol state up
volume bigraid state down
plex name myvol.p0 state up org concat vol myvol
plex name myvol.p1 state up org concat vol myvol
plex name myvol.p2 state init org striped 512b vol myvol
plex name bigraid.p0 state initializing org raid5 512b vol bigraid
sd name myvol.p0.s0 drive a plex myvol.p0 state up len 1048576b driveoffset 265b plexoffset 0b
sd name myvol.p0.s1 drive b plex myvol.p0 state up len 1048576b driveoffset 265b plexoffset 1048576b
sd name myvol.p1.s0 drive c plex myvol.p1 state up len 1048576b driveoffset 265b plexoffset 0b
sd name myvol.p1.s1 drive d plex myvol.p1 state up len 1048576b driveoffset 265b plexoffset 1048576b
sd name myvol.p2.s0 drive a plex myvol.p2 state init len 524288b driveoffset 1048841b plexoffset 0b
sd name myvol.p2.s1 drive b plex myvol.p2 state init len 524288b driveoffset 1048841b plexoffset 524288b
sd name myvol.p2.s2 drive c plex myvol.p2 state init len 524288b driveoffset 1048841b plexoffset 1048576b
sd name myvol.p2.s3 drive d plex myvol.p2 state init len 524288b driveoffset 1048841b plexoffset 1572864b
sd name bigraid.p0.s0 drive a plex bigraid.p0 state initializing len 4194304b driveoff set 1573129b plexoffset 0b
sd name bigraid.p0.s1 drive b plex bigraid.p0 state initializing len 4194304b driveoff set 1573129b plexoffset 4194304b
sd name bigraid.p0.s2 drive c plex bigraid.p0 state initializing len 4194304b driveoff set 1573129b plexoffset 8388608b
sd name bigraid.p0.s3 drive d plex bigraid.p0 state initializing len 4194304b driveoff set 1573129b plexoffset 12582912b
sd name bigraid.p0.s4 drive e plex bigraid.p0 state initializing len 4194304b driveoff set 1573129b plexoffset 16777216bgeom_vinum_load="YES"# gvinum l -rv root# bsdlabel -e devnameMounting root from ufs:/dev/gvinum/root...
Subdisk root.p0.s0:
Size: 125829120 bytes (120 MB)
State: up
Plex root.p0 at offset 0 (0 B)
Drive disk0 (/dev/da0h) at offset 135680 (132 kB)
Subdisk root.p1.s0:
Size: 125829120 bytes (120 MB)
State: up
Plex root.p1 at offset 0 (0 B)
Drive disk1 (/dev/da1h) at offset 135680 (132 kB)...
8 partitions:
# size offset fstype [fsize bsize bps/cpg]
a: 245760 281 4.2BSD 2048 16384 0 # (Cyl. 0*- 15*)
c: 71771688 0 unused 0 0 # (Cyl. 0 - 4467*)
h: 71771672 16 vinum # (Cyl. 0*- 4467*)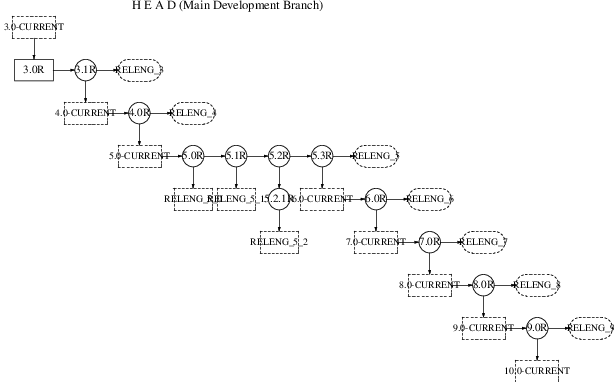
OFF#!/bin/sh ①
. /etc/rc.subr ②
name="dummy" ③
start_cmd="${name}_start" ④
stop_cmd=":" ⑤
dummy_start() ⑥
{
echo "Nothing started."
}
load_rc_config $name ⑦
run_rc_command "$1" ⑧# /etc/rc.d/dummy start#!/bin/sh
. /etc/rc.subr
name=dummy
rcvar=dummy_enable ①
start_cmd="${name}_start"
stop_cmd=":"
load_rc_config $name ②
: ${dummy_enable:=no} ③
: ${dummy_msg="Nothing started."} ④
dummy_start()
{
echo "$dummy_msg" ⑤
}
run_rc_command "$1"start_cmd="echo \"$dummy_msg\""#!/bin/sh
. /etc/rc.subr
name=mumbled
rcvar=mumbled_enable
command="/usr/sbin/${name}" ①
load_rc_config $name
run_rc_command "$1"#!/bin/sh
. /etc/rc.subr
name=mumbled
rcvar=mumbled_enable
command="/usr/sbin/${name}"
command_args="mock arguments > /dev/null 2>&1" ①
pidfile="/var/run/${name}.pid" ②
required_files="/etc/${name}.conf /usr/share/misc/${name}.rules" ③
sig_reload="USR1" ④
start_precmd="${name}_prestart" ⑤
stop_postcmd="echo Bye-bye" ⑥
extra_commands="reload plugh xyzzy" ⑦
plugh_cmd="mumbled_plugh" ⑧
xyzzy_cmd="echo 'Nothing happens.'"
mumbled_prestart()
{
if checkyesno mumbled_smart; then ⑨
rc_flags="-o smart ${rc_flags}" ⑩
fi
case "$mumbled_mode" in
foo)
rc_flags="-frotz ${rc_flags}"
;;
bar)
rc_flags="-baz ${rc_flags}"
;;
*)
warn "Invalid value for mumbled_mode" ⑪
return 1 ⑫
;;
esac
run_rc_command xyzzy ⑬
return 0
}
mumbled_plugh() ⑭
{
echo 'A hollow voice says "plugh".'
}
load_rc_config $name
run_rc_command "$1"# /etc/rc.d/mumbled
Usage: /etc/rc.d/mumbled [fast|force|one](start|stop|restart|rcvar|reload|plugh|xyzzy|status|poll)if checkyesno mumbled_enable; then
foo
fiif checkyesno "${mumbled_enable}"; then
foo
fi#!/bin/sh
# PROVIDE: mumbled oldmumble ①
# REQUIRE: DAEMON cleanvar frotz ②
# BEFORE: LOGIN ③
# KEYWORD: nojail shutdown ④
. /etc/rc.subr
name=mumbled
rcvar=mumbled_enable
command="/usr/sbin/${name}"
start_precmd="${name}_prestart"
mumbled_prestart()
{
if ! checkyesno frotz_enable && \
! /etc/rc.d/frotz forcestatus 1>/dev/null 2>&1; then
force_depend frotz || return 1 ⑤
fi
return 0
}
load_rc_config $name
run_rc_command "$1"#!/bin/sh
. /etc/rc.subr
name="dummy"
start_cmd="${name}_start"
stop_cmd=":"
kiss_cmd="${name}_kiss"
extra_commands="kiss"
dummy_start()
{
if [ $# -gt 0 ]; then ①
echo "Greeting message: $*"
else
echo "Nothing started."
fi
}
dummy_kiss()
{
echo -n "A ghost gives you a kiss"
if [ $# -gt 0 ]; then ②
echo -n " and whispers: $*"
fi
case "$*" in
*[.!?])
echo
;;
*)
echo .
;;
esac
}
load_rc_config $name
run_rc_command "$@" ③# /etc/rc.d/dummy start
Nothing started.
# /etc/rc.d/dummy start Hello world!
Greeting message: Hello world!# /etc/rc.d/dummy kiss
A ghost gives you a kiss.
# /etc/rc.d/dummy kiss Once I was Etaoin Shrdlu...
A ghost gives you a kiss and whispers: Once I was Etaoin Shrdlu...#!/bin/sh
. /etc/rc.subr
name="dummy"
start_cmd="${name}_start"
stop_cmd=":"
: ${dummy_svcj_options:=""} ①
dummy_start()
{
echo "Nothing started."
}
load_rc_config $name
run_rc_command "$1"#!/bin/sh
. /etc/rc.subr
name="dummy"
start_cmd="${name}_start"
stop_cmd=":"
dummy_start()
{
echo "Nothing started."
}
load_rc_config $name
dummy_svcj="NO" # 在 svcj 中运行没有意义 ①
run_rc_command "$1"#!/bin/sh
#
# PROVIDE: dummy
# REQUIRE: NETWORKING SERVERS
# KEYWORD: shutdown
#
# 将以下行添加到 /etc/rc.conf.local 或 /etc/rc.conf
# 以启用此服务:
#
# dummy_enable (bool): 设置为 YES 以在启动时启用 dummy。
# 默认值:NO
# dummy_user (string): 运行时使用的用户账户。
# 默认值:www
#
. /etc/rc.subr
case $0 in ①
/etc/rc*)
# 在启动(关机)时,$0 是 /etc/rc (/etc/rc.shutdown),
# 所以从 $_file 获取脚本的名称
name=$_file
;;
*)
name=$0
;;
esac
name=${name##*/} ②
rcvar="${name}_enable" ③
desc="该服务的简短描述"
command="/usr/local/sbin/dummy"
load_rc_config "$name"
eval "${rcvar}=\${${rcvar}:-'NO'}" ④
eval "${name}_svcj_options=\${${name}_svcj_options:-'net_basic'}" ⑤
eval "_dummy_user=\${${name}_user:-'www'}" ⑥
_dummy_configname=/usr/local/etc/${name}.cfg ⑦
pidfile=/var/run/dummy/${name}.pid
required_files ${_dummy_configname}
command_args="-u ${_dummy_user} -c ${_dummy_configfile} -p ${pidfile}"
run_rc_command "$1"# ln -s dummy /usr/local/etc/rc.d/dummy_foo
# sysrc dummy_foo_enable=YES
# service dummy_foo start# /etc/rc.d/dummy onestart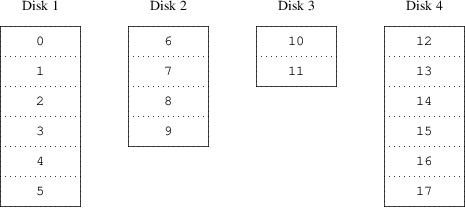


% whoami
alice
% ls -l `which su`
-r-sr-xr-x 1 root wheel 10744 Dec 6 19:06 /usr/bin/su
% su -
Password: xi3kiune
# whoami
root% whoami
eve
% ssh [email protected]
[email protected]'s password:
% god
Last login: Thu Oct 11 09:52:57 2001 from 192.168.0.1
Copyright (c) 1980, 1983, 1986, 1988, 1990, 1991, 1993, 1994
The Regents of the University of California. All rights reserved.
FreeBSD 4.4-STABLE (LOGIN) 4: Tue Nov 27 18:10:34 PST 2001
Welcome to FreeBSD!
%sshd auth required pam_nologin.so no_warn
sshd auth required pam_unix.so no_warn try_first_pass
sshd account required pam_login_access.so
sshd account required pam_unix.so
sshd session required pam_lastlog.so no_fail
sshd password required pam_permit.sologin auth required pam_nologin.so no_warnauth required pam_nologin.so no_warn# cd /etc/pam.d
# ln -s su sudo/*-
* Copyright (c) 2002,2003 Networks Associates Technology, Inc.
* All rights reserved.
*
* 本软件由 ThinkSec AS 和 Network Associates Laboratories(Network Associates, Inc. 的安全研究部门)为 FreeBSD 项目开发,
* 由 DARPA/SPAWAR 合同 N66001-01-C-8035(“CBOSS”)支持,作为 DARPA CHATS 研究项目的一部分。
*
* 允许在源代码和二进制形式中进行再分发和使用,无论是否修改,前提是满足以下条件:
* 1. 源代码的再分发必须保留上述版权声明、此条件列表和以下免责声明。
* 2. 二进制形式的再分发必须在分发的文档和/或其他材料中重现上述版权声明、此条件列表和以下免责声明。
* 3. 未经特定的书面许可,不得使用作者的名字来支持或推广基于此软件的产品。
*
* 本软件由作者和贡献者“按原样”提供,不提供任何明示或暗示的保证,包括但不限于适销性和适用性保证,
* 对于任何直接、间接、附带、特殊、示范性或间接损害(包括但不限于采购替代商品或服务;使用、数据或利润的丧失;
* 或商业中断)在任何理论的责任下,无论是基于合同、严格责任或侵权(包括过失或其他)产生的,
* 即使在已被告知此类损害的可能性的情况下,也不承担责任。
*
* $P4: //depot/projects/openpam/bin/su/su.c#10 $
* $FreeBSD: head/en_US.ISO8859-1/articles/pam/su.c 38826 2012-05-17 19:12:14Z hrs $
*/
#include <sys/param.h>
#include <sys/wait.h>
#include <err.h>
#include <pwd.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <syslog.h>
#include <unistd.h>
#include <security/pam_appl.h>
#include <security/openpam.h> /* openpam_ttyconv() 需要 */
extern char **environ;
static pam_handle_t *pamh;
static struct pam_conv pamc;
static void
usage(void)
{
fprintf(stderr, "Usage: su [login [args]]\n");
exit(1);
}
int
main(int argc, char *argv[])
{
char hostname[MAXHOSTNAMELEN];
const char *user, *tty;
char **args, **pam_envlist, **pam_env;
struct passwd *pwd;
int o, pam_err, status;
pid_t pid;
while ((o = getopt(argc, argv, "h")) != -1)
switch (o) {
case 'h':
default:
usage();
}
argc -= optind;
argv += optind;
if (argc > 0) {
user = *argv;
--argc;
++argv;
} else {
user = "root";
}
/* 初始化 PAM */
pamc.conv = &openpam_ttyconv;
pam_start("su", user, &pamc, &pamh);
/* 设置一些项目 */
gethostname(hostname, sizeof(hostname));
if ((pam_err = pam_set_item(pamh, PAM_RHOST, hostname)) != PAM_SUCCESS)
goto pamerr;
user = getlogin();
if ((pam_err = pam_set_item(pamh, PAM_RUSER, user)) != PAM_SUCCESS)
goto pamerr;
tty = ttyname(STDERR_FILENO);
if ((pam_err = pam_set_item(pamh, PAM_TTY, tty)) != PAM_SUCCESS)
goto pamerr;
/* 验证申请人 */
if ((pam_err = pam_authenticate(pamh, 0)) != PAM_SUCCESS)
goto pamerr;
if ((pam_err = pam_acct_mgmt(pamh, 0)) == PAM_NEW_AUTHTOK_REQD)
pam_err = pam_chauthtok(pamh, PAM_CHANGE_EXPIRED_AUTHTOK);
if (pam_err != PAM_SUCCESS)
goto pamerr;
/* 建立请求的凭证 */
if ((pam_err = pam_setcred(pamh, PAM_ESTABLISH_CRED)) != PAM_SUCCESS)
goto pamerr;
/* 认证成功;打开会话 */
if ((pam_err = pam_open_session(pamh, 0)) != PAM_SUCCESS)
goto pamerr;
/* 获取映射的用户名;PAM 可能已更改它 */
pam_err = pam_get_item(pamh, PAM_USER, (const void **)&user);
if (pam_err != PAM_SUCCESS || (pwd = getpwnam(user)) == NULL)
goto pamerr;
/* 导出 PAM 环境变量 */
if ((pam_envlist = pam_getenvlist(pamh)) != NULL) {
for (pam_env = pam_envlist; *pam_env != NULL; ++pam_env) {
putenv(*pam_env);
free(*pam_env);
}
free(pam_envlist);
}
/* 构建参数列表 */
if ((args = calloc(argc + 2, sizeof *args)) == NULL) {
warn("calloc()");
goto err;
}
*args = pwd->pw_shell;
memcpy(args + 1, argv, argc * sizeof *args);
/* fork 和 exec */
switch ((pid = fork())) {
case -1:
warn("fork()");
goto err;
case 0:
/* 子进程:放弃权限并启动一个 shell */
/* 设置 uid 和组 */
if (initgroups(pwd->pw_name, pwd->pw_gid) == -1) {
warn("initgroups()");
_exit(1);
}
if (setgid(pwd->pw_gid) == -1) {
warn("setgid()");
_exit(1);
}
if (setuid(pwd->pw_uid) == -1) {
warn("setuid()");
_exit(1);
}
execve(*args, args, environ);
warn("execve()");
_exit(1);
default:
/* 父进程:等待子进程退出 */
waitpid(pid, &status, 0);
/* 关闭会话并释放 PAM 资源 */
pam_err = pam_close_session(pamh, 0);
pam_end(pamh, pam_err);
exit(WEXITSTATUS(status));
}
pamerr:
fprintf(stderr, "抱歉\n");
err:
pam_end(pamh, pam_err);
exit(1);
}/*-
* 版权所有 (c) 2002 Networks Associates Technology, Inc.
* 保留所有权利。
*
* 本软件是由 ThinkSec AS 和 Network Associates Laboratories(Network Associates, Inc. 安全研究部门)为 FreeBSD 项目开发的,
* 根据 DARPA/SPAWAR 合同 N66001-01-C-8035 ("CBOSS"),作为 DARPA CHATS 研究计划的一部分。
*
* 允许以源代码或二进制形式进行再分发和使用,无论是否修改,前提是满足以下条件:
* 1. 源代码的再分发必须保留上述版权声明、此条件列表和以下免责声明。
* 2. 二进制形式的再分发必须在分发的文档和/或其他材料中复制上述版权声明、此条件列表和以下免责声明。
* 3. 未经特定的书面许可,不得使用作者的姓名来支持或推广基于本软件的产品。
*
* 本软件由作者和贡献者以“原样”提供,不提供任何明示或暗示的保证,包括但不限于适销性和适合某一特定用途的暗示保证。
* 在任何情况下,作者或贡献者都不对因使用本软件而导致的任何直接、间接、偶然、特殊、示范性或间接损害负责,
* 包括但不限于替代商品或服务的采购;使用、数据或利润的损失;或业务中断,不论是在合同、严格责任或侵权(包括过失或其他)下,
* 即使已经被告知可能发生此类损害,也不承担任何责任。
*
* $P4: //depot/projects/openpam/modules/pam\_unix/pam\_unix.c#3 \$
* $FreeBSD: head/en\_US.ISO8859-1/articles/pam/pam\_unix.c 38826 2012-05-17 19:12:14Z hrs \$
*/
#include <sys/param.h>
#include <pwd.h>
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <security/pam_modules.h>
#include <security/pam_appl.h>
#ifndef _OPENPAM
static char password_prompt[] = "Password:";
#endif
#ifndef PAM_EXTERN
#define PAM_EXTERN
#endif
PAM_EXTERN int
pam_sm_authenticate(pam_handle_t *pamh, int flags,
int argc, const char *argv[])
{
#ifndef _OPENPAM
struct pam_conv *conv;
struct pam_message msg;
const struct pam_message *msgp;
struct pam_response *resp;
#endif
struct passwd *pwd;
const char *user;
char *crypt_password, *password;
int pam_err, retry;
/* identify user */
if ((pam_err = pam_get_user(pamh, &user, NULL)) != PAM_SUCCESS)
return (pam_err);
if ((pwd = getpwnam(user)) == NULL)
return (PAM_USER_UNKNOWN);
/* get password */
#ifndef _OPENPAM
pam_err = pam_get_item(pamh, PAM_CONV, (const void **)&conv);
if (pam_err != PAM_SUCCESS)
return (PAM_SYSTEM_ERR);
msg.msg_style = PAM_PROMPT_ECHO_OFF;
msg.msg = password_prompt;
msgp = &msg;
#endif
for (retry = 0; retry < 3; ++retry) {
#ifdef _OPENPAM
pam_err = pam_get_authtok(pamh, PAM_AUTHTOK,
(const char **)&password, NULL);
#else
resp = NULL;
pam_err = (*conv->conv)(1, &msgp, &resp, conv->appdata_ptr);
if (resp != NULL) {
if (pam_err == PAM_SUCCESS)
password = resp->resp;
else
free(resp->resp);
free(resp);
}
#endif
if (pam_err == PAM_SUCCESS)
break;
}
if (pam_err == PAM_CONV_ERR)
return (pam_err);
if (pam_err != PAM_SUCCESS)
return (PAM_AUTH_ERR);
/* compare passwords */
if ((!pwd->pw_passwd[0] && (flags & PAM_DISALLOW_NULL_AUTHTOK)) ||
(crypt_password = crypt(password, pwd->pw_passwd)) == NULL ||
strcmp(crypt_password, pwd->pw_passwd) != 0)
pam_err = PAM_AUTH_ERR;
else
pam_err = PAM_SUCCESS;
#ifndef _OPENPAM
free(password);
#endif
return (pam_err);
}
PAM_EXTERN int
pam_sm_setcred(pam_handle_t *pamh, int flags,
int argc, const char *argv[])
{
return (PAM_SUCCESS);
}
PAM_EXTERN int
pam_sm_acct_mgmt(pam_handle_t *pamh, int flags,
int argc, const char *argv[])
{
return (PAM_SUCCESS);
}
PAM_EXTERN int
pam_sm_open_session(pam_handle_t *pamh, int flags,
int argc, const char *argv[])
{
return (PAM_SUCCESS);
}
PAM_EXTERN int
pam_sm_close_session(pam_handle_t *pamh, int flags,
int argc, const char *argv[])
{
return (PAM_SUCCESS);
}
PAM_EXTERN int
pam_sm_chauthtok(pam_handle_t *pamh, int flags,
int argc, const char *argv[])
{
return (PAM_SERVICE_ERR);
}
#ifdef PAM_MODULE_ENTRY
PAM_MODULE_ENTRY("pam_unix");
#endif/*-
* 版权所有 (c) 2002 Networks Associates Technology, Inc.
* 保留所有权利。
*
* 本软件是由 ThinkSec AS 和 Network Associates Laboratories(Network Associates, Inc. 安全研究部门)为 FreeBSD 项目开发的,
* 根据 DARPA/SPAWAR 合同 N66001-01-C-8035 ("CBOSS"),作为 DARPA CHATS 研究计划的一部分。
*
* 允许以源代码或二进制形式进行再分发和使用,无论是否修改,前提是满足以下条件:
* 1. 源代码的再分发必须保留上述版权声明、此条件列表和以下免责声明。
* 2. 二进制形式的再分发必须在分发的文档和/或其他材料中复制上述版权声明、此条件列表和以下免责声明。
* 3. 未经特定的书面许可,不得使用作者的姓名来支持或推广基于本软件的产品。
*
* 本软件由作者和贡献者以“原样”提供,不提供任何明示或暗示的保证,包括但不限于适销性和适合某一特定用途的暗示保证。
* 在任何情况下,作者或贡献者都不对因使用本软件而导致的任何直接、间接、偶然、特殊、示范性或间接损害负责,
* 包括但不限于替代商品或服务的采购;使用、数据或利润的损失;或业务中断,不论是在合同、严格责任或侵权(包括过失或其他)下,
* 即使已经被告知可能发生此类损害,也不承担任何责任。
*
* $FreeBSD: head/en_US.ISO8859-1/articles/pam/converse.c 38826 2012-05-17 19:12:14Z hrs $
*/
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <security/pam_appl.h>
int
converse(int n, const struct pam_message **msg,
struct pam_response **resp, void *data)
{
struct pam_response *aresp;
char buf[PAM_MAX_RESP_SIZE];
int i;
data = data;
if (n <= 0 || n > PAM_MAX_NUM_MSG)
return (PAM_CONV_ERR);
if ((aresp = calloc(n, sizeof *aresp)) == NULL)
return (PAM_BUF_ERR);
for (i = 0; i < n; ++i) {
aresp[i].resp_retcode = 0;
aresp[i].resp = NULL;
switch (msg[i]->msg_style) {
case PAM_PROMPT_ECHO_OFF:
aresp[i].resp = strdup(getpass(msg[i]->msg));
if (aresp[i].resp == NULL)
goto fail;
break;
case PAM_PROMPT_ECHO_ON:
fputs(msg[i]->msg, stderr);
if (fgets(buf, sizeof buf, stdin) == NULL)
goto fail;
aresp[i].resp = strdup(buf);
if (aresp[i].resp == NULL)
goto fail;
break;
case PAM_ERROR_MSG:
fputs(msg[i]->msg, stderr);
if (strlen(msg[i]->msg) > 0 &&
msg[i]->msg[strlen(msg[i]->msg) - 1] != '\n')
fputc('\n', stderr);
break;
case PAM_TEXT_INFO:
fputs(msg[i]->msg, stdout);
if (strlen(msg[i]->msg) > 0 &&
msg[i]->msg[strlen(msg[i]->msg) - 1] != '\n')
fputc('\n', stdout);
break;
default:
goto fail;
}
}
*resp = aresp;
return (PAM_SUCCESS);
fail:
for (i = 0; i < n; ++i) {
if (aresp[i].resp != NULL) {
memset(aresp[i].resp, 0, strlen(aresp[i].resp));
free(aresp[i].resp);
}
}
memset(aresp, 0, n * sizeof *aresp);
*resp = NULL;
return (PAM_CONV_ERR);
}options COM_MULTIPORTdevice sio1 at isa? port 0x100 flags 0x1005
device sio2 at isa? port 0x108 flags 0x1005
device sio3 at isa? port 0x110 flags 0x1005
device sio4 at isa? port 0x118 flags 0x1005
...
device sio15 at isa? port 0x170 flags 0x1005
device sio16 at isa? port 0x178 flags 0x1005 irq 3device cy0 at isa? irq 10 iomem 0xd4000 iosiz 0x2000# cd /dev
# for i in 0 1 2 3 4 5 6 7;do ./MAKEDEV cuac$i ttyc$i;doneINS8250 -> INS8250B
\
\
\-> INS8250A -> INS82C50A
\
\
\-> NS16450 -> NS16C450
\
\
\-> NS16550 -> NS16550A -> PC16550DError (6)...Timeout interrupt failed: IIR = c1 LSR = 61device sio4 at isa? port 0x100 flags 0xb05
device sio5 at isa? port 0x108 flags 0xb05
device sio6 at isa? port 0x110 flags 0xb05
device sio7 at isa? port 0x118 flags 0xb05
device sio8 at isa? port 0x120 flags 0xb05
device sio9 at isa? port 0x128 flags 0xb05
device sio10 at isa? port 0x130 flags 0xb05
device sio11 at isa? port 0x138 flags 0xb05 irq 9o o o *
Port A |
o * o *
Port B |
o * o o
IRQ 2 3 4 5Diode
+---------->|-------+
/ |
o * o o | 1 kOhm
Port A +----|######|-------+
o * o o | |
Port B `-------------------+ ==+==
o * o o | Ground
\ |
+--------->|-------+
IRQ 2 3 4 5 Diode# 标准的板载 COM1 端口
device sio0 at isa? port "IO_COM1" flags 0x10
# 修补过的多功能 I/O 扩展板
options COM_MULTIPORT
device sio1 at isa? port "IO_COM2" flags 0x205
device sio2 at isa? port "IO_COM3" flags 0x205 irq 3sio0: irq maps: 0x1 0x11 0x1 0x1
sio0 at 0x3f8-0x3ff irq 4 flags 0x10 on isa
sio0: type 16550A
sio1: irq maps: 0x1 0x9 0x1 0x1
sio1 at 0x2f8-0x2ff flags 0x205 on isa
sio1: type 16550A (multiport)
sio2: irq maps: 0x1 0x9 0x1 0x1
sio2 at 0x3e8-0x3ef irq 3 flags 0x205 on isa
sio2: type 16550A (multiport master)device si0 at isa? iomem 0xd0000 irq 11device si0# cd /dev
# ./MAKEDEV ttyAnn cuaAnnttyA01 "/usr/libexec/getty std.9600" vt100 on insecureflags
0x1005sio1 at 0x100-0x107 flags 0x1005 on isa
sio1: type 16550A (multiport)
sio2 at 0x108-0x10f flags 0x1005 on isa
sio2: type 16550A (multiport)
sio3 at 0x110-0x117 flags 0x1005 on isa
sio3: type 16550A (multiport)
sio4 at 0x118-0x11f flags 0x1005 on isa
sio4: type 16550A (multiport)
sio5 at 0x120-0x127 flags 0x1005 on isa
sio5: type 16550A (multiport)
sio6 at 0x128-0x12f flags 0x1005 on isa
sio6: type 16550A (multiport)
sio7 at 0x130-0x137 flags 0x1005 on isa
sio7: type 16550A (multiport)
sio8 at 0x138-0x13f flags 0x1005 on isa
sio8: type 16550A (multiport)
sio9 at 0x140-0x147 flags 0x1005 on isa
sio9: type 16550A (multiport)
sio10 at 0x148-0x14f flags 0x1005 on isa
sio10: type 16550A (multiport)
sio11 at 0x150-0x157 flags 0x1005 on isa
sio11: type 16550A (multiport)
sio12 at 0x158-0x15f flags 0x1005 on isa
sio12: type 16550A (multiport)
sio13 at 0x160-0x167 flags 0x1005 on isa
sio13: type 16550A (multiport)
sio14 at 0x168-0x16f flags 0x1005 on isa
sio14: type 16550A (multiport)
sio15 at 0x170-0x177 flags 0x1005 on isa
sio15: type 16550A (multiport)
sio16 at 0x178-0x17f irq 3 flags 0x1005 on isa
sio16: type 16550A (multiport master)# dmesg | more# cd /dev
# ./MAKEDEV tty1
# ./MAKEDEV cua1
(中间的其他条目)
# ./MAKEDEV ttyg
# ./MAKEDEV cuag# echo at > ttyd*ttyc0 "/usr/libexec/getty std.38400" unknown on insecure
ttyc1 "/usr/libexec/getty std.38400" unknown on insecure
ttyc2 "/usr/libexec/getty std.38400" unknown on insecure
...
ttyc7 "/usr/libexec/getty std.38400" unknown on insecurelinux_faccessatnamei(9)openatioctlioctlint clone_flags = (CLONE_VM | CLONE_FS | CLONE_FILES | CLONE_SIGNAL
| CLONE_SETTLS | CLONE_PARENT_SETTID
| CLONE_CHILD_CLEARTID | CLONE_SYSVSEM
#if __ASSUME_NO_CLONE_DETACHED == 0
| CLONE_DETACHED
#endif
| 0);#define CLONE_SIGNAL (CLONE_SIGHAND | CLONE_THREAD)if (__predict_true(p->p_sysent != &elf_Linux(R)_sysvec))
return;...
AUE_FORK STD { int linux_fork(void); }
...
AUE_CLOSE NOPROTO { int close(int fd); }
......
#define LINUX_SYS_linux_fork 2
...
#define LINUX_SYS_close 6
...struct linux_fork_args {
register_t dummy;
};{ 0, (sy_call_t *)linux_fork, AUE_FORK, NULL, 0, 0 }, /* 2 = linux_fork */
{ AS(close_args), (sy_call_t *)close, AUE_CLOSE, NULL, 0, 0 }, /* 6 = close */static int
translate_traps(int signal, int trap_code)
{
if (signal != SIGBUS)
return signal;
switch (trap_code) {
case T_PROTFLT:
case T_TSSFLT:
case T_DOUBLEFLT:
case T_PAGEFLT:
return SIGSEGV;
default:
return signal;
}
}struct linux_emuldata {
pid_t pid;
int *child_set_tid; /* 在 clone() 中:子进程的 TID 设置地址 */
int *child_clear_tid;/* 在 clone() 中:子进程的 TID 清除地址 */
struct linux_emuldata_shared *shared;
int pdeath_signal; /* 父进程死亡信号 */
LIST_ENTRY(linux_emuldata) threads; /* linux 线程的链表 */
};struct linux_emuldata_shared {
int refs;
pid_t group_pid;
LIST_HEAD(, linux_emuldata) threads; /* linux 线程链表的头部 */
};struct linux_emuldata *em_find(struct proc *, int locked);int linux_clone(l_int flags, void *stack, void *parent_tidptr, int dummy,
void * child_tidptr);mov %edx,%gs:0x10pthread_mutex_lock(&mutex);
...
pthread_mutex_unlock(&mutex);int futex(void *uaddr, int op, int val, struct timespec *timeout, void *uaddr2, int val3);struct futex {
void *f_uaddr;
int f_refcount;
LIST_ENTRY(futex) f_list;
TAILQ_HEAD(lf_waiting_paroc, waiting_proc) f_waiting_proc;
};struct waiting_proc {
struct thread *wp_t;
struct futex *wp_new_futex;
TAILQ_ENTRY(waiting_proc) wp_list;
};oldval = *uaddr2
*uaddr2 = oldval OP oparg文件描述符 123 = /tmp/foo/, 当前工作目录 = /tmp/
openat(123, /tmp/bah, flags, mode) /* 打开 /tmp/bah */
openat(123, bah, flags, mode) /* 打开 /tmp/foo/bah */
openat(AT_FDCWD, bah, flags, mode) /* 打开 /tmp/bah */
openat(stdio, bah, flags, mode) /* 返回错误,因为 stdio 不是一个目录 */openat() --> kern_openat() --> vn_open() -> namei()publicvm info guesttmuxtmuxboot 命令,简化了配置。-i interfacevm reset <名称> – 强制重置虚拟机(类似按下重置键)。1. pkg install vm-bhyve [grub2-bhyve sysutils/bhyve-firmware]
2. zfs create pool/vm
3. sysrc vm_enable="YES"
4. sysrc vm_dir="zfs:pool/vm"
5. vm init
6. cp /usr/local/share/examples/vm-bhyve/* /mountpoint/for/pool/vm/.templates/
7. vm switch create public
8. vm switch add public em0
9. vm iso ftp://ftp.freebsd.org/pub/FreeBSD/releases/ISO-IMAGES/10.3/FreeBSD-10.3-RELEASE-amd64-bootonly.iso
10. vm create myguest
11. vm install [-f] myguest FreeBSD-10.3-RELEASE-amd64-bootonly.iso
12. vm console myguestvm create -t 我的模板名 myguestloader="bhyveload"
cpu=2
memory=512M
disk0_type="virtio-blk"
disk0_name="disk0.img"
disk0_dev="file"
network0_type="virtio-net"
network0_switch="public"vm set console=tmux# vm list | grep fbsd
fbsd default bhyveload 2 256M - No Running (88761)
# tmux ls
fbsd: 1 windows (created Tue Jun 28 10:42:22 2016) [168x46]cpu=1
memory=512Mguest="freebsd"
loader="bhyveload"guest="windows"
uefi="yes"
disk0_type="ahci-hd"
# 若低于 Windows 10,则需要设置 sectorsize
disk0_opts="sectorsize=512"guest="generic"
loader="grub"
grub_install0="knetbsd -h -r cd0a /netbsd"
grub_install1="boot"
grub_run0="knetbsd -h -r ld0a (hd0,msdos1)/netbsd"
grub_run1="boot"loader="grub"
cpu=1
memory=256M
network0_type="virtio-net"
network0_switch="public"
disk0_type="virtio-blk"
disk0_name="disk0.img"
grub_install0="kopenbsd -h com0 /6.2/amd64/bsd.rd"
grub_run0="kopenbsd -h com0 -r sd0a /bsd"
bhyve_options="-w"loader="grub"
cpu=1
memory=256M
network0_type="virtio-net"
network0_switch="public"
disk0_type="virtio-blk"
disk0_name="disk0.img"
grub_run_partition="openbsd4"
grub_run0="kopenbsd -h com0 -r sd0d /bsd"
bhyve_options="-w"vm create -t resflash resflash-vm
vm configure resflash-vm
cd /my/vm/resflash-vm
fetch https://stable.rcesoftware.com/pub/resflash/6.2/amd64/install/resflash-amd64-com0-115200-20171202_1952.img.gz
gunzip resflash-amd64-com0-115200-20171202_1952.img.gz
mv resflash-amd64-com0-115200-20171202_1952.img disk0.img
vm -f start resflash-vmloader="uefi"
uefi_vars="yes"
cpu=4
memory=8G
network0_type="virtio-net"
network0_switch="public"
disk0_type="virtio-blk"
disk0_name="disk0.img"
bhyve_options="-w"
graphics="yes"
xhci_mouse="yes"
graphics_res="1920x1080"loader="uefi"
cpu=4
memory=4G
network0_type="virtio-net"
network0_switch="public"
disk0_name="disk0"
disk0_type="virtio-blk"
disk0_dev="sparse-zvol"
disk0_size="1T"
#bhyve_options="-w"
graphics="yes"
xhci_mouse="yes"
graphics_res="1920x1080"loader="grub"
cpu=1
memory=512M
network0_type="virtio-net"
network0_switch="public"
disk0_type="virtio-blk"
disk0_name="disk0.img"
grub_install0="linux /boot/vmlinuz-virt initrd=/boot/initramfs-virt alpine_dev=cdrom:iso9660 modules=loop,squashfs,sd-mod,usb-storage,sr-mod"
grub_install1="initrd /boot/initramfs-virt"
grub_run0="linux /boot/vmlinuz-virt root=/dev/vda3 modules=ext4"
grub_run1="initrd /boot/initramfs-virt"guest="linux"
loader="grub"
grub_install0="linux /boot/grsec initrd=/boot/initramfs-grsec alpine_dev=cdrom:iso9660 modules=loop,squashfs,sd-mod,usb-storage,sr-mod"
grub_install1="initrd /boot/initramfs-grsec"
grub_install2="boot"
grub_run_partition="msdos1"
grub_run0="linux /boot/vmlinuz-grsec root=/dev/vda3 modules=ext4"
grub_run1="initrd /boot/initramfs-grsec"
grub_run2="boot"guest="linux"
loader="grub"
grub_install0="linux /isolinux/vmlinuz"
grub_install1="initrd /isolinux/initrd.img"
grub_install2="boot"
grub_run_partition="msdos1"
grub_run0="linux /vmlinuz-2.6.32-573.el6.x86_64 root=/dev/mapper/VolGroup-lv_root"
grub_run1="initrd /initramfs-2.6.32-573.el6.x86_64.img"
grub_run2="boot"guest="linux"
loader="grub"
grub_install0="linux /isolinux/vmlinuz"
grub_install1="initrd /isolinux/initrd.img"
grub_install2="boot"
grub_run_partition="msdos1"
grub_run_dir="/grub2"guest="linux"
loader="grub"
grub_install0="linux /isolinux/vmlinuz"
grub_install1="initrd /isolinux/initrd.img"
grub_install2="boot"
grub_run_partition="msdos1"
grub_run0="linux /vmlinuz-2.6.32-431.el6.x86_64 root=/dev/mapper/VolGroup-lv_root"
grub_run1="initrd /initramfs-2.6.32-431.el6.x86_64.img"
grub_run2="boot"guest="linux"
loader="grub"
grub_run_partition="msdos1"grub_run_dir="/grub"
grub_run_file="grub.cfg"loader="uefi"
cpu=2
memory=2G
network0_type="virtio-net"
network0_switch="public"
disk0_type="ahci-hd"
disk0_name="disk0.img"
disk0_size="10G"
graphics="yes"
xhci_mouse="yes"
graphics_res="1024x768"
graphics_wait="yes"
uefi_vars="yes"loader="uefi"
cpu=4
memory=8G
network0_type="virtio-net"
network0_switch="public"
graphics="yes"
xhci_mouse="yes"
graphics_res="1920x1080"
zfs_zvol_opts="volblocksize=128k"
disk0_name="disk0"
disk0_dev="sparse-zvol"
disk0_type="virtio-blk"
disk0_size="1T"loader="grub"
disk0_opts="sectorsize=512"
grub_install0="linux /live/vmlinuz console=ttyS0 console=tty0 quiet initrd=/live/initrd.img boot=live nopersistent noautologin nonetworking nouser hostname=vyos"
grub_install1="initrd /live/initrd.img"
grub_install2="boot"loader="grub"
cpu=2
memory="4G"
network0_type="virtio-net"
network0_switch="wan"
disk0_type="virtio-blk"
disk0_name="chr-6.44.5.img"
grub_run0="linux /boot/vmlinuz-64 crashkernel=16M"
grub_run1="initrd /boot/initrd.rgz"loader="grub"
cpu=1
memory=256M
grub_install0="linux /boot/gentoo root=/dev/ram0 init=/linuxrc dokeymap looptype=squashfs loop=/image.squashfs cdroot"
grub_install1="initrd /boot/gentoo.igz"
network0_type="virtio-net"
network0_switch="public"
disk0_type="virtio-blk"
disk0_name="disk0.img"loader="grub"
cpu=1
memory=1024M
network0_type="virtio-net"
network0_switch="public"
disk0_type="virtio-blk"
disk0_name="disk0.img"
network0_mac="58:9c:fc:0e:4b:da"
grub_run_partition="2"
grub_run_dir="/grub"loader="uefi-csm"
cpu=2
memory=512M
network0_type="e1000"
network0_switch="public"
disk0_type="ahci-hd"
disk0_name="openwrt-19.07.1-x86-64-combined-ext4.img"sudo vm iso https://downloads.openwrt.org/releases/24.10.0/targets/x86/64/openwrt-24.10.0-x86-64-generic-ext4-combined-efi.img.gzloader="uefi"
graphics="yes"
xhci_mouse="yes"
graphics_res="1920x1080"
cpu=2
memory=512M
disk0_type="virtio-blk"
disk0_name="disk0.img"
debug="yes"
network0_type="virtio-net"
network0_switch="openwrt"
network1_type="virtio-net"
network1_switch="public"disk0_type="virtio-blk"
disk0_name="disk0.img"disk0_type="virtio-blk"
disk0_name="disk0"
disk0_dev="sparse-zvol"disk0_type="virtio-blk"
disk0_name="/dev/ada10"
disk0_dev="custom"disk0_type="virtio-blk"
disk0_name="disk0.img"
disk0_opts="nocache,direct"# zfs create -sV 50G -o volmode=dev path/to/dataset/zvol# vm configure myguest
disk1_name="/dev/zvol/path/to/dataset/zvol"
disk1_type="virtio-blk"
disk1_dev="custom"# vm configure myguest
disk1_type="virtio-9p"
disk1_name="sharename=/path/to/share"
disk1_dev="custom"# mount -t 9p -o trans=virtio sharename /local/mount/point/of/sharesharename /local/mount/point/of/share 9p trans=virtio,rw 0 0network0_type="virtio-net"
network0_switch="public"network0_type="virtio-net"
network0_switch="public"
network0_mac="00:11:22:33:44:55"network0_type="virtio-net"
network0_device="tap0"vm_dir="zfs:sys/data/vm"# vm datastore list
NAME TYPE PATH ZFS DATASET
default zfs /data/vm sys/data/vm# vm datastore add <名称> <存储规范># vm datastore add ssd zfs:sys/data/vm2
# vm datastore list
NAME TYPE PATH ZFS DATASET
default zfs /data/vm sys/data/vm
ssd zfs /data/vm2 sys/data/vm2# vm datastore remove <名称># vm create -d ssd -t centos7 -s 50G centos-ssd# vm list
NAME DATASTORE LOADER CPU MEMORY AUTOSTART STATE
alpine default grub 1 512M No Stopped
centos default grub 1 512M Yes [1] Stopped
wintest default none 2 2G No Running (15087)
fb2 ssd bhyveload 1 256M No Stopped
# vm info fb2
------------------------
Virtual Machine: fb2
------------------------
state: stopped
datastore: ssd
....# vm switch list
NAME TYPE IFACE ADDRESS PRIVATE MTU VLAN PORTS
public standard vm-public 192.168.8.1/24 no - - -# vm switch info public
------------------------
Virtual Switch: public
------------------------
type: auto
ident: bridge0
vlan: -
nat: -
physical-ports: re0
bytes-in: 385868007 (367.992M)
bytes-out: 401540470 (382.938M)
virtual-port
device: tap1
vm: wintest# vm switch create public
# vm switch add public em0# vm switch vlan public 10# vm switch vlan public 0# vm switch create -t manual -b bridge0 customswitchgateway_enable="yes"
pf_enable="yes"nat on em0 from {192.168.8.0/24} to any -> (em0)# sysctl net.inet.ip.forwarding=1
# service pf start# vm switch create -a 192.168.8.1/24 public <-- 如果是新建交换机
# vm switch address public 192.168.8.1/24 <-- 如果已有交换机可直接使用
# vm switch list
NAME TYPE IDENT ADDRESS PRIVATE MTU VLAN PORTS
public standard - 192.168.8.1/24 no - - -network0_type="virtio-net"
network0_switch="public"root@test:~ # cat /etc/rc.conf
...
ifconfig_vtnet0="192.168.8.2/24"
defaultrouter="192.168.8.1"
root@test:~ # ping 192.168.8.1
64 bytes from 192.168.8.1: icmp_seq=0 ttl=64 time=0.135 ms
root@test:~ # ping 8.8.8.8
64 bytes from 8.8.8.8: icmp_seq=0 ttl=54 time=12.199 msport=0
domain-needed
no-resolv
except-interface=lo0
bind-interfaces
local-service
dhcp-authoritative
interface=vm-public
dhcp-range=192.168.8.10,192.168.8.254grub_run_dir="/grub2"grub_run_dir="/grub2"
grub_run_file="grub2.conf"grub_run_partition="2"grub_run_partition="2"
grub_run0="linux /vmlinuz"grub> knetbsd -h -r ld0a /netbsd
grub> bootgrub_run0="knetbsd -h -r ld0a /netbsd"grub_install0="linux /isolinux/vmlinuz"
grub_install1="initrd /isolinux/initrd.img"# pkg install bhyve-firmware# vm create -t windows winguest# vm install winguest Windows-Installer.iso# vm install winguest virtio-installer.isodisk1_type="ahci-cd"
disk1_dev="custom"
disk1_name="/full/path/to/virtio-installer.iso"cpu=8
cpu_sockets=2
cpu_cores=4
cpu_threads=1disk0_type="nvme"
disk0_name="disk0.img"
disk0_opts="maxq=16,qsz=8,ioslots=1,sectsz=512,ser=ABCDEFGH"loader="uefi"
graphics="yes"
xhci_mouse="yes"
cpu=2
memory=8G
network0_type="e1000"
network0_switch="public"
utctime="no"
passthru0="4/0/0"vm iso https://downloads.omniosce.org/media/stable/omniosce-r151028b.isovm create omniosceloader="uefi"
graphics="yes"
network0_type="virtio-net"vm install omniosce omnios-r151040g.iso0.0.0.0:5900Creating root pool with: zpool create -f rpool c1t0d0
internal error: Argument out of domainecho -h > /mnt/boot/configcat << EOM > /mnt/boot/conf.d/serial
console="ttya,text"
os_console="ttya"
ttya-mode="115200,8,n,1,-"
EOMsysctl net.link.tap.up_on_open=1
sysctl net.link.bridge.ipfw=0
sysctl net.link.bridge.pfil_bridge=0
sysctl net.link.bridge.pfil_member=0# 禁用在网络桥上传输的数据包过滤:
net.link.bridge.pfil_bridge=0
net.link.bridge.pfil_member=0error: file `/boot/vmlinuz-vanilla' not found.
error: you need to load the kernel first.
Press any key to continue...ls (cd0)/
apks/ boot/ efi/grub> ls (cd0)/boot/
config-virt dtbs-virt/ grub/ initramfs-virt modloop-virt syslinux/ System.map-virt vmlinuz-virt# pkg install uefi-edk2-bhyvegraphics="yes"xhci_mouse="yes"# /boot/loader.conf
hw.usb.usbhid.enable=1
usbhid_load="YES"graphics_listen="1.2.3.4"graphics_port="5901"graphics_res="1600x900"1920x1200
1920x1080
1600x1200
1600x900
1280x1024
1280x720
1024x768
800x600
640x480graphics_wait="yes"------------------------
Virtual Machine: fbsd
------------------------
state: running (33508)
datastore: default
loader: bhyveload
uuid: e5881af2-53ed-11e6-b442-50e549369bc6
uefi: no
cpu: 2
memory: 256M
memory-resident: 21311488 (20.324M)
console-ports
com1: tmux/fbsd
network-interface
number: 0
emulation: virtio-net
virtual-switch: public
fixed-mac-address: 58:9c:fc:01:a1:ce
fixed-device: -
active-device: tap2
desc: vmnet-fbsd-0-public
mtu: 1500
bridge: bridge0
bytes-in: 206873 (202.024K)
bytes-out: 850 (850.000B)
virtual-disk
number: 0
device-type: file
emulation: virtio-blk
options: -
system-path: /data/vm/fbsd/disk0.img
bytes-size: 21474836480 (20.000G)
bytes-used: 379974656 (362.372M)------------------------
Virtual Switch: public
------------------------
type: auto
ident: bridge0
vlan: -
nat: -
physical-ports: re0
bytes-in: 628193006 (599.091M)
bytes-out: 1421559466 (1.323G)
virtual-port
device: tap1
vm: win2GRUB_CMDLINE_LINUX_DEFAULT=""
GRUB_CMDLINE_LINUX="console=tty0 console=ttyS0,115200n8"
GRUB_TERMINAL="serial console"
GRUB_SERIAL_COMMAND="serial --speed=115200 --unit=0 --word=8 --parity=no --stop=1"GRUB_CMDLINE_LINUX="console=tty1 console=ttyS0,115200"
GRUB_TERMINAL="console serial"
GRUB_SERIAL_COMMAND="serial --speed=115200"GRUB_CMDLINE_LINUX_DEFAULT=""
# 保留之前的值 (...) 然后添加控制台配置
GRUB_CMDLINE_LINUX="... console=tty0 console=ttyS0,115200n8"
GRUB_TERMINAL_OUTPUT="serial console"
GRUB_SERIAL_COMMAND="serial --speed=115200 --unit=0 --word=8 --parity=no --stop=1"kernelopts=$(grub2-editenv - list | grep kernelopts)
grub2-editenv - set "$kernelopts console=tty0 console=ttyS0,115200"vm migrate -s guest-name new-hostvm migrate [-s12t] [-r name] [-i snapshot] [-d datastore] guest hostpkg install qemuvm img https://download.freebsd.org/ftp/releases/VM-IMAGES/14.0-RELEASE/amd64/Latest/FreeBSD-14.0-RELEASE-amd64.raw.xz
vm create -t freebsd-zvol -i FreeBSD-14.0-RELEASE-amd64.raw freebsd-cloud
vm start freebsd-cloudpkg install cdrkit-genisoimagevm img https://cloud-images.ubuntu.com/noble/current/noble-server-cloudimg-amd64.img
vm create -t ubuntu-cloud -i noble-server-cloudimg-amd64.img -C -k ~/.ssh/id_rsa.pub ubuntu-server
vm start ubuntu-server
Starting ubuntu-server
* found guest in /zroot/vm/ubuntu-server
* booting...
ssh [email protected]
The authenticity of host '192.168.0.91 (192.168.0.91)' can't be established.
ECDSA key fingerprint is SHA256:6s9uReyhsIXRv0dVRcBCKMHtY0kDYRV7zbM7ot6u604.
No matching host key fingerprint found in DNS.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added '192.168.0.91' (ECDSA) to the list of known hosts.
Welcome to Ubuntu 24.04.1 LTS (GNU/Linux 6.8.0-45-generic x86_64)# ➜ .templates cat ubuntu-cloud.conf
loader="uefi"
uefi_vars="yes"
cpu=4
memory=4096M
network0_type="virtio-net"
network0_switch="public"
graphics="yes"
xhci_mouse="yes"
graphics_res="1600x900"
zfs_zvol_opts="volblocksize=128k"
disk0_name="disk0"
disk0_dev="sparse-zvol"
disk0_type="virtio-blk"全局变量 - ${ALL_CAPS}
局部变量 - ${_variable}lib::function_name# 检查某条件
if [ test ]; then
code
fi
# 检查其他条件
if [ test2 ]; then
code2
fi[ "check err" ] && util::err "Some error"
[ "check ok" ] || util::err "Another error"lib::good_function(){
[ "check err condition" ] && return 1
main_code_block
}
lib::bad_function(){
if [ "check ok condition" ]; then
main_code_block
else
return 1
fi
}lib::good_function(){
local _var="$1"
setvar "${_var}" "return value"
}
lib::bad_function(){
echo "return value"
}
_variable=$(lib::bad_function)
lib::good_function "_variable"case "${_variable}" in
one) func_one ;;
two) func_two ;;
three) func_three ;;
esacGandi.netrsync.net% cd .git/hooks
% ln -s ../../.hooks/prepare-commit-msg% git config --add core.hooksPath .hooks% cd .git/hooks
% ln -s ../../tools/tools/git/hooks/prepare-commit-msggit rebase -i main stagingmx2.FreeBSD.org 排除在 SPF 检查之外。grep -r 更快速。make indexmake describe# 按优先顺序列出用于签名的首选算法(从强到弱)
personal-digest-preferences SHA512 SHA384 SHA256 SHA224
# 新密钥的默认首选项
default-preference-list SHA512 SHA384 SHA256 SHA224 AES256 CAMELLIA256 AES192 CAMELLIA192 AES CAMELLIA128 CAST5 BZIP2 ZLIB ZIP Uncompressed% gpg --full-gen-key
gpg (GnuPG) 2.1.8; Copyright (C) 2015 Free Software Foundation, Inc.
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law.
Warning: using insecure memory!
Please select what kind of key you want:
(1) RSA and RSA (default)
(2) DSA and Elgamal
(3) DSA (sign only)
(4) RSA (sign only)
Your selection? 1
RSA keys may be between 1024 and 4096 bits long.
What keysize do you want? (2048) 2048 ①
Requested keysize is 2048 bits
Please specify how long the key should be valid.
0 = key does not expire
<n> = key expires in n days
<n>w = key expires in n weeks
<n>m = key expires in n months
<n>y = key expires in n years
Key is valid for? (0) 3y ②
Key expires at Wed Nov 4 17:20:20 2015 MST
Is this correct? (y/N) y
GnuPG needs to construct a user ID to identify your key.
Real name: Chucky Daemon ③
Email address: [email protected]
Comment:
You selected this USER-ID:
"Chucky Daemon <[email protected]>"
Change (N)ame, (C)omment, (E)mail or (O)kay/(Q)uit? o
You need a Passphrase to protect your secret key.% ssh kpasswd.freebsd.org% kpasswd% git clone -o freebsd --config remote.freebsd.fetch='+refs/notes/*:refs/notes/*' https://git.freebsd.org/${repo}.git% git remote -v
freebsd https://git.freebsd.org/${repo}.git (fetch)
freebsd https://git.freebsd.org/${repo}.git (push)% gen-gitconfig.sh
[...]
% git config user.name (your name in gecos)
% git config user.email (your login)@FreeBSD.org% git config --add remote.freebsd.fetch '+refs/internal/*:refs/internal/*'
% git fetch
% git checkout -b admin internal/admingit worktree add -b admin ../${repo}-admin internal/admingit push freebsd HEAD:refs/internal/admin% git clone -o freebsd $URL -b branch [<directory>]% git clone -o freebsd -b branch --depth 1 $URL [dir]% cd src
% make buildworld
% make buildkernel
% make installkernel
% make installworld% git pull --ff-only% git checkout 08b8197a74Note: checking out '08b8197a742a96964d2924391bf9fdfeb788865d'.
You are in a 'detached HEAD' state. You can look around, make experimental
changes and commit them, and you can discard any commits you make in this
state without impacting any branches by performing another checkout.
If you want to create a new branch to retain commits you create, you may
do so (now or later) by using -b with the checkout command again. Example:
git checkout -b <new-branch-name>
HEAD is now at 08b8197a742a hook gpiokeys.4 to the build5ef0bd68b515 (HEAD -> main, freebsd/main, freebsd/HEAD) HEAD@{0}: pull --ff-only: Fast-forward
a8163e165c5b (upstream/main) HEAD@{1}: checkout: moving from b6fb97efb682994f59b21fe4efb3fcfc0e5b9eeb to main
...% git bisect start --first-parent
% git bisect good a8163e165c5b
% git bisect bad HEAD
Bisecting: 1722 revisions left to test after this (roughly 11 steps)
[c427b3158fd8225f6afc09e7e6f62326f9e4de7e] Fixup r361997 by balancing parens. Duh.% git config --add user.signingKey LONG-KEY-ID
% git config --add commit.gpgSign true
% git config --add tag.gpgSign true
% git config --add push.gpgSign if-askedcategory/port: 总结。
描述你为什么做成这些修改。
PR: 12345% cd src
% git checkout main
% git checkout -b no-color-ls
% cd bin/ls
% vi ls.c # 进行更改
% git diff # 查看更改
diff --git a/bin/ls/ls.c b/bin/ls/ls.c
index 7378268867ef..cfc3f4342531 100644
--- a/bin/ls/ls.c
+++ b/bin/ls/ls.c
@@ -66,6 +66,7 @@ __FBSDID("$FreeBSD$");
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
+#undef COLORLS
#ifdef COLORLS
#include <termcap.h>
#include <signal.h>
% # 这些更改看起来不错,进行提交...
% git commit ls.c% git checkout main
% git pull --ff-only
% git rebase -i main no-color-lsAuto-merging bin/ls/ls.c
CONFLICT (content): Merge conflict in bin/ls/ls.c
error: could not apply 646e0f9cda11... no color ls
Resolve all conflicts manually, mark them as resolved with
"git add/rm <conflicted_files>", then run "git rebase --continue".
You can instead skip this commit: run "git rebase --skip".
To abort and get back to the state before "git rebase", run "git rebase --abort".
Could not apply 646e0f9cda11... no color ls<<<<<<< HEAD
#ifdef COLORLS_NEW
#include <terminfo.h>
=======
#undef COLORLS
#ifdef COLORLS
#include <termcap.h>
>>>>>>> 646e0f9cda11... no color ls
....#undef COLORLS_NEW
#ifdef COLORLS_NEW
#include <terminfo.h>
....% git add ls.c
% git rebase --continue
....% git checkout main
% # 在此构建并安装...% git checkout no-color-ls
% git checkout -b no-color-ls-stable-12 # 为该分支创建另一个名称
% git rebase -i stable/12 no-color-ls --onto main% git checkout stable/X
% git cherry-pick -x $HASH --edit% git checkout stable/X
% git cherry-pick -x $HASH -m 1 --edit% git checkout releng/13.0
% git cherry-pick -x $HASH --edit% git checkout -b tmp-branch stable/X
% for h in $HASH_LIST; do git cherry-pick -x $h; done
% git rebase -i stable/X
# 将每个提交(除了第一个)标记为 'squash'
# 如果需要,更新提交信息以反映所有提交的元素。
# 确保保留 "cherry picked from" 行。
% git push freebsd HEAD:stable/X% git checkout stable/X
% git pull
% git checkout tmp-branch
% git rebase stable/X
% git push freebsd HEAD:stable/X% git checkout stable/X
% git branch -d tmp-branch% git cherry-pick -x -m 1 $HASH% git cherry-pick --abort
% git cherry-pick -x -m 2 $HASH% git reset --hard freebsd/stable/12% git worktree add ../mtree vendor/NetBSD/mtree% cd ../mtree
% rsync -va --del --exclude=".git" ~/git/NetBSD/usr.sbin/mtree/ .
% git add -A
% git status
...
% git diff --staged
...
% git commit -m "Vendor import of NetBSD's mtree at 2020-12-11"
[vendor/NetBSD/mtree 8e7aa25fcf1] Vendor import of NetBSD's mtree at 2020-12-11
7 files changed, 114 insertions(+), 82 deletions(-)
% git tag -a vendor/NetBSD/mtree/20201211% git push --follow-tags freebsd vendor/NetBSD/mtree% cd ../src
% git subtree merge -P contrib/mtree vendor/NetBSD/mtree% cd ../src # 进入仓库顶层目录
% git checkout -b XXX # 为合并创建一个新的临时 XXX 分支
% git fetch freebsd # 获取来自上游的更改
% git merge freebsd/main # 合并更改并解决冲突
% git checkout -b YYY freebsd/main # 创建一个新的临时 YYY 分支以重新操作
% git subtree merge -P contrib/mtree vendor/NetBSD/mtree # 重新进行子树合并
% git checkout XXX . # XXX 分支包含了解决冲突的内容
% git commit -c XXX~1 # -c 使用重新基准化之前的提交消息
% git diff XXX YYY # 应该为空
% git show YYY # 应该只包含你想要的更改,并且是来自供应商分支的合并提交% git checkout -B YYY freebsd/main # 如果重新开始更容易,可以创建一个新的临时 YYY 分支% git push freebsd YYY:main # 将提交推送到上游的 'main' 分支
% git branch -D XXX # 删除临时的 XXX 分支
% git branch -D YYY # 删除临时的 YYY 分支% git checkout -B XXX YYY # 重新创建临时分支 XXX 并切换到它
% git merge freebsd/main # 合并更改并解决冲突
% git checkout -B YYY freebsd/main # 重新创建新的临时分支 YYY 以重新操作
% git subtree merge -P contrib/mtree vendor/NetBSD/mtree # 重新进行子树合并
% git checkout XXX . # XXX 分支包含了解决冲突的内容
% git commit -c XXX~1 # -c 重新使用重新基准化之前的提交消息% cd /some/where
% mkdir glorbnitz
% cd glorbnitz
% git init
% git checkout -b vendor/glorbnitz% cp -r ~/glorbnitz/* .
% git add *% git commit -m "Import GlorbNitz frobnosticator revision 3.1415"% cd /path/to/freebsd/repo/src
% git remote add glorbnitz /some/where/glorbnitz
% git fetch glorbnitz vendor/glorbnitz% git worktree add ../glorbnitz vendor/glorbnitz
% cd ../glorbnitz
% git tag --annotate vendor/glorbnitz/3.1415
# 确保提交正确,可以使用 "git show" 查看
% git push --follow-tags freebsd vendor/glorbnitz% cd ../src
% git subtree add -P contrib/glorbnitz vendor/glorbnitz
# 确保提交正常,可以使用 "git show"
% git commit --amend # 最后的提交消息检查
% git push freebsd% git config --global pull.ff only% cd freebsd-src
% git checkout main
% git pull (--ff-only|--rebase)% cd freebsd-src
% git checkout main
% git fetch freebsd
% git merge --ff-only freebsd/main% git rebase -i main working% git remote set-url --push freebsd ssh://[email protected]/src.gitfreefall% gen-gitconfig.sh% git push freebsd working:main% git checkout working
% git fetch freebsd
% git rebase freebsd/main
% git push freebsd working:main% git checkout main
% git merge --ff-only `working`
% git push freebsd% git pull --rebase
% git push freebsd% git log% git log --grep revision=XXXX% git clone -o freebsd --config remote.freebsd.fetch='+refs/notes/*:refs/notes/*' $URL freebsd-current% cd freebsd-current
% git worktree add ../freebsd-stable-12 stable/12% cd freebsd-current
% git checkout main
% git pull --ff-only
# 从上游的更改现在已本地化,并且当前树已更新
% cd ../freebsd-stable-12
% git merge --ff-only freebsd/stable/12
# 现在你的 stable/12 也已更新% git branch issue # 创建 'issue' 分支
% git reset --hard freebsd/main # 将 'main' 重置回官方的提交
% git checkout issue # 回到原先的地方# 我们在 wilma 分支上
% git checkout fred # 切换到 fred 分支
% git cherry-pick wilma # 拷贝误提交的提交
% git checkout wilma # 回到 wilma 分支
% git reset --hard HEAD^ # 将 wilma 回退到上一个提交% git checkout pre-split # 回到起点
% git branch -D fred # 删除 fred 分支
% git checkout -B wilma # 重置 wilma 分支
% git branch -d pre-split # 假装什么也没发生% git reflog
6ff9c25 (HEAD -> wilma) HEAD@{0}: rebase -i (finish): returning to refs/heads/wilma
6ff9c25 (HEAD -> wilma) HEAD@{1}: rebase -i (start): checkout main
869cbd3 HEAD@{2}: rebase -i (start): checkout wilma
a6a5094 (fred) HEAD@{3}: rebase -i (finish): returning to refs/heads/fred
a6a5094 (fred) HEAD@{4}: rebase -i (pick): Encourage contributions
1ccd109 (freebsd/main, main) HEAD@{5}: rebase -i (start): checkout main
869cbd3 HEAD@{6}: rebase -i (start): checkout fred
869cbd3 HEAD@{7}: checkout: moving from wilma to fred
869cbd3 HEAD@{8}: commit: Encourage contributions
...
%% git checkout -B wilma 869cbd3
% git branch -D fred% git checkout 869cbd3
M faq.md
Note: checking out '869cbd3'.
You are in 'detached HEAD' state. You can look around, make experimental
changes and commit them, and you can discard any commits you make in this
state without impacting any branches by performing another checkout.
If you want to create a new branch to retain commits you create, you may
do so (now or later) by using -b with the checkout command again. Example:
git checkout -b <new-branch-name>
HEAD is now at 869cbd3 Encourage contributions
% git checkout -B wilma% git checkout worker
% git checkout -b feature # 创建一个新的分支
% git cherry-pick main..async # 将变更引入% git checkout driver # 检出 driver 分支
% git checkout -b kernel # 创建 kernel 分支
% git checkout -b userland # 创建 userland 分支% git rebase -i main kernel% git rebase -i main userland% git checkout kernel
% git log driver
% git cherry-pick $HASH% git reset HEAD^git add -i foo/bar.c% git clone --mirror $URL% git clone --mirror https://git.freebsd.org/ports.git ports.git
% cd ports.git
% git worktree add ../ports main
% git worktree add ../quarterly branches/2020Q4
% cd ../portsfetch = +refs/heads/*:refs/remotes/freebsd/*git config --add remote.freebsd.fetch '+refs/*:refs/freebsd/*'git log refs/freebsd/vendor/zlib/1.2.10% git remote -v
freebsd https://git.freebsd.org/src.git (fetch)
freebsd ssh://[email protected]/src.git (push)% git remote add github [email protected]:gvnn3/freebsd-src.git
% git remote -v
github [email protected]:gvnn3/freebsd-src.git (fetch)
github [email protected]:gvnn3/freebsd-src.git (push)
freebsd https://git.freebsd.org/src.git (fetch)
freebsd ssh://[email protected]/src.git (push)% git checkout -b gnn-pr2001-fix% git push github
fatal: The current branch gnn-pr2001-fix has no upstream branch.
To push the current branch and set the remote as upstream, use
git push --set-upstream github gnn-pr2001-fix% git push --set-upstream github gnn-feature
Enumerating objects: 20486, done.
Counting objects: 100% (20486/20486), done.
Delta compression using up to 8 threads
Compressing objects: 100% (12202/12202), done.
Writing objects: 100% (20180/20180), 56.25 MiB | 13.15 MiB/s, done.
Total 20180 (delta 11316), reused 12972 (delta 7770), pack-reused 0
remote: Resolving deltas: 100% (11316/11316), completed with 247 local objects.
remote:
remote: Create a pull request for 'gnn-feature' on GitHub by visiting:
remote: https://github.com/gvnn3/freebsd-src/pull/new/gnn-feature
remote:
To github.com:gvnn3/freebsd-src.git
* [new branch] gnn-feature -> gnn-feature
Branch 'gnn-feature' set up to track remote branch 'gnn-feature' from 'github'.% git push
Enumerating objects: 4, done.
Counting objects: 100% (4/4), done.
Delta compression using up to 8 threads
Compressing objects: 100% (2/2), done.
Writing objects: 100% (3/3), 314 bytes | 1024 bytes/s, done.
Total 3 (delta 1), reused 1 (delta 0), pack-reused 0
remote: Resolving deltas: 100% (1/1), completed with 1 local object.
To github.com:gvnn3/freebsd-src.git
9e5243d7b659..cf6aeb8d7dda gnn-feature -> gnn-feature% git remote -v
freebsd https://git.freebsd.org/src.git (fetch)
freebsd ssh://[email protected]/src.git (push)
github https://github.com/freebsd/freebsd-src (fetch)
github https://github.com/freebsd/freebsd-src (fetch)% git fetch github pull/$PR/head:staging
% git rebase -i main staging # 将 staging 分支更新到最新,调整提交信息
<进行必要的测试>
% git checkout main
% git pull --ff-only # 若时间已过,确保拉取最新的提交
% git checkout main
% git merge --ff-only staging
<再次测试如果需要>
% git push freebsd --push-option=confirm-authorsender_dependent_relayhost_maps = hash:/usr/local/etc/postfix/relayhost_maps
smtp_sasl_auth_enable = yes
smtp_sasl_security_options = noanonymous
smtp_sasl_password_maps = hash:/usr/local/etc/postfix/sasl_passwd
smtp_use_tls = yes你的用户名@FreeBSD.org [smtp.freebsd.org]:587[smtp.freebsd.org]:587 你的用户名:你的密码smtpd_sender_login_maps = hash:/usr/local/etc/postfix/sender_login_maps
smtpd_sender_restrictions = reject_known_sender_login_mismatch你的用户名@FreeBSD.org 你的本地用户名action "freebsd" relay host smtp+tls://[email protected]:587 auth <secrets>
match from any auth 你的本地用户名 mail-from "_你的用户名[email protected]" for any action "freebsd"freebsd 你的用户名:你的密码Routers section: (在列表顶部)
freebsd_send:
driver = manualroute
domains = !+local_domains
transport = freebsd_smtp
route_data = ${lookup {${lc:$sender_address}} lsearch {/usr/local/etc/exim/freebsd_send}}
Transport Section:
freebsd_smtp:
driver = smtp
tls_certificate=<local certificate>
tls_privatekey=<local certificate private key>
tls_require_ciphers = EECDH+ECDSA+AESGCM:EECDH+aRSA+AESGCM:EECDH+ECDSA+SHA384:EECDH+ECDSA+SHA256:EECDH+aRSA+SHA384:EECDH+aRSA+SHA256:EECDH+AESGCM:EECDH:EDH+AESGCM:EDH+aRSA:HIGH:!MEDIUM:!LOW:!aNULL:!eNULL:!LOW:!RC4:!MD5:!EXP:!PSK:!SRP:!DSS
dkim_domain = <local DKIM domain>
dkim_selector = <local DKIM selector>
dkim_private_key= <local DKIM private key>
dnssec_request_domains = *
hosts_require_auth = smtp.freebsd.org
Authenticators:
freebsd_plain:
driver = plaintext
public_name = PLAIN
client_send = ^example/mail^examplePassword
client_condition = ${if eq{$host}{smtp.freebsd.org}}[email protected]:smtp.freebsd.org::587Reviewed by: 用户名Reviewed by: 全名 <有效的@email> (maintainer)...
PR: 12345...
Reviewed by: -arch...
Approved by: abc (maintainer)...
Obtained from: OpenBSD...
MFC after: 2 weeksPR: 54321
Reviewed by: -arch
Obtained from: NetBSD
MFC after: 1 month
Relnotes: yes/*
* SPDX-License-Identifier: BSD-2-Clause
*
* Copyright (c) [year] [your name]
*
* Redistribution and use in source and binary forms, with or without
* modification, are permitted provided that the following conditions
* are met:
* 1. Redistributions of source code must retain the above copyright
* notice, this list of conditions and the following disclaimer.
* 2. Redistributions in binary form must reproduce the above copyright
* notice, this list of conditions and the following disclaimer in the
* documentation and/or other materials provided with the distribution.
*
* THIS SOFTWARE IS PROVIDED BY THE AUTHOR AND CONTRIBUTORS ``AS IS'' AND
* ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
* IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE
* ARE DISCLAIMED. IN NO EVENT SHALL THE AUTHOR OR CONTRIBUTORS BE LIABLE
* FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
* DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS
* OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION)
* HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT
* LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY
* OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF
* SUCH DAMAGE.
*
* [id for your version control system, if any]
*/% git -C /path/to/repo shortlog -sne --since="2 years" -- relative/path/to/fileSUBDIR += newport% git add category/Makefile category/newport
% git commit
% git push# make package
# make deinstall
# pkg add 上述构建的包
# make deinstall
# make reinstall
# make package`% git checkout 2021Q2
% git cherry-pick -x $HASH
(验证一切是否正常,例如通过构建测试)
% git push% git remote set-url --push freebsd [email protected]:${repo}.git% git remote -v
freebsd https://git.freebsd.org/${repo}.git (fetch)
freebsd [email protected]:${repo}.git (push)Approved by: 导师的用户名 (mentor)Approved by: re (用户名)